
Ⅰ. 군집화 후속 분석
군집
- k-means 이용
- k 값은 3~6개 사이에서 elbow method로 결정
- 너무 크며 군집 후 사후 분석이 어렵기 떄문에 적절하게 찾아야 함.
사후 분석
- 군집 결과를 label(y)로 간주
- 각 군집의 비즈니스 특징 도출 (시각화를 이용하려 특징 도출 → sns.pairplot
- 각 고객 군에 대한 마케팅 전략 수립
Ⅱ. 군집화 후속분석 - 고객 세분화
1. 환경준비
(1) 라이브러리 로딩
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import silhouette_score(2) Data Loading
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/customer_segmentation.csv'
data = pd.read_csv(path)
data.head()
2. 데이터 전처리
# 군집화는 아래 변수들만 사용합니다.
x = data.loc[:, ['Age', 'Income', 'Score']]
scaler = MinMaxScaler()
x_s = scaler.fit_transform(x)
3. 클러스터링
(1) k-means 모델 만들기
- k값을 늘려가면서(2~20) 모델을 만들고, inertia 값 혹은 실루엣 점수를 저장
- 그래프를 통해서 최적의 k값 결정 (데이터가 적으므로 3~6사이의 값으로 하는걸 추천)
- 선정된 k값으로 모델을 생성
# k의 갯수에 따라 각 점과의 거리를 계산하여 적정한 k를 찾아 봅시다.
kvalues = range(2,20)
inertias = []
sil_score = []
for k in kvalues:
model = KMeans(n_clusters=k, n_init = 'auto', random_state = 10)
pred = model.fit_predict(x_s)
inertias.append(model.inertia_) # 이너시아
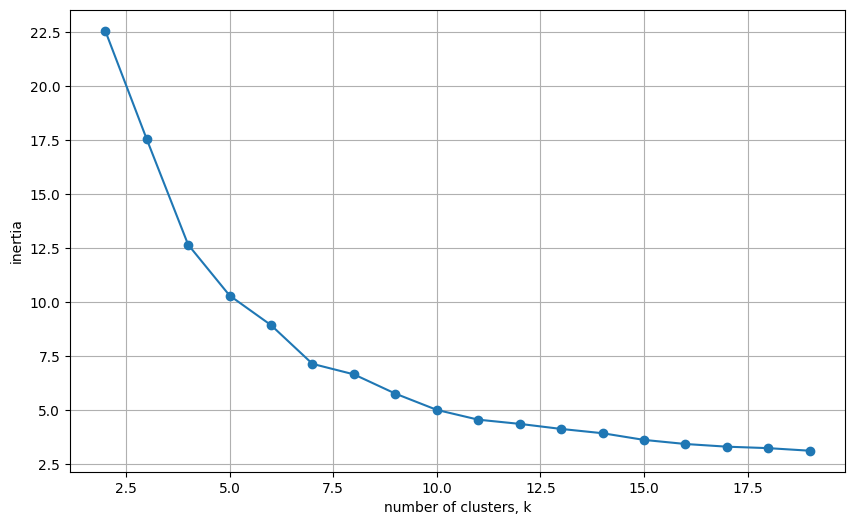
sil_score.append(silhouette_score(x_s, pred)) # 실루엣# inertias plot
plt.figure(figsize = (10,6))
plt.plot(kvalues, inertias, '-o')
plt.xlabel('number of clusters, k')
plt.ylabel('inertia')
plt.grid()
plt.show()- 꺾이는 부분이 명확하지 않아 elbow method 적용하기 어려움
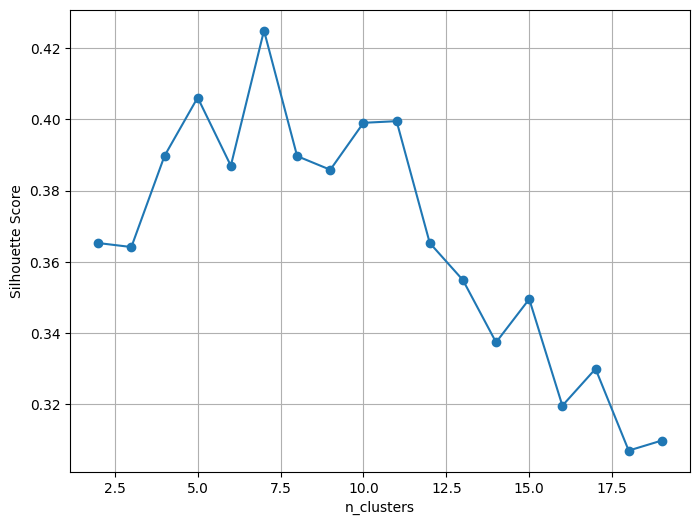
# 실루엣 점수 시각화
plt.figure(figsize = (8, 6))
plt.plot(kvalues, sil_score, marker='o')
plt.xlabel('n_clusters')
plt.ylabel('Silhouette Score')
plt.grid()
plt.show()- 실루엣을 보니 7이 가장 높은걸 알 수 있음
- but, 데이터나 적다보니 7로 나누면 너무 세분화 될 것 같아서 5로 결정
model = KMeans(n_clusters=5, n_init = 'auto', random_state = 10)
model.fit(x_s)
(2) 데이터 군집 결과 정리
- 데이터를 군집화 하여 기존 데이터와 합치기
- pd.concat([data, pred], axis = 1)
# 예측
pred = model.predict(x_s)
# 예측 결과를 데이터프레임으로 만들고
pred = pd.DataFrame(pred, columns = ['pred'])
# 원본 데이터와 합치기
result = pd.concat([data, pred], axis = 1)
# 예측 결과는 카테고리 타입으로 변경
result['pred'] = pd.Categorical(result['pred'] )
result.head()
4. 후속 분석
(1) 군집별 변수 비교
# 수치형 변수와 군집간 관계를 분석하는 차트 함수
def var_analysis(var, data = result):
plt.figure(figsize = (14,4))
plt.subplot(1,3,1)
sns.barplot(x = 'pred', y = var, data = data)
plt.grid()
plt.subplot(1,3,2)
sns.kdeplot(x = var, data = data, hue = 'pred', common_norm = False)
plt.grid()
plt.subplot(1,3,3)
sns.boxplot(x = var, y = 'pred', data = data)
plt.grid()
plt.tight_layout()
plt.show()(1) Age
var = 'Age'
var_analysis(var)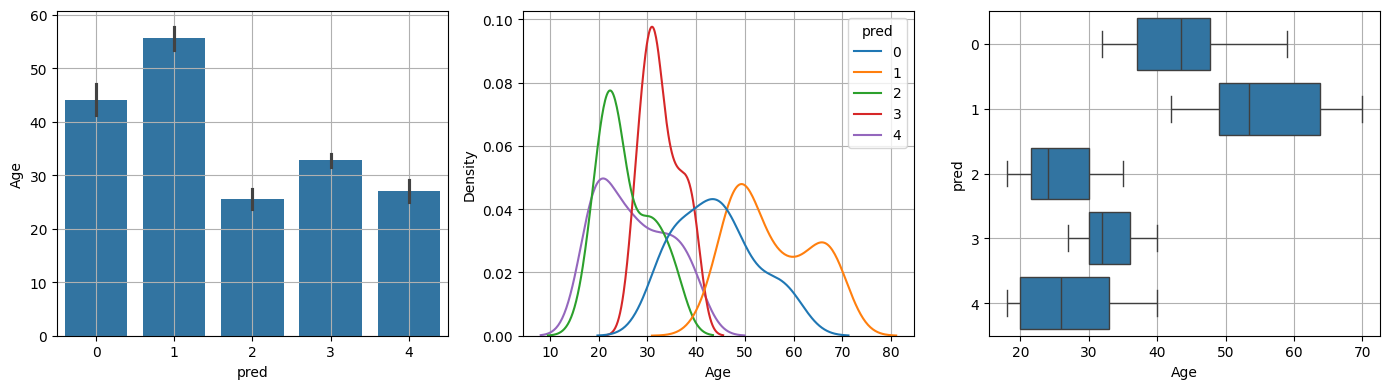
(2) Income
var = 'Income'
var_analysis(var)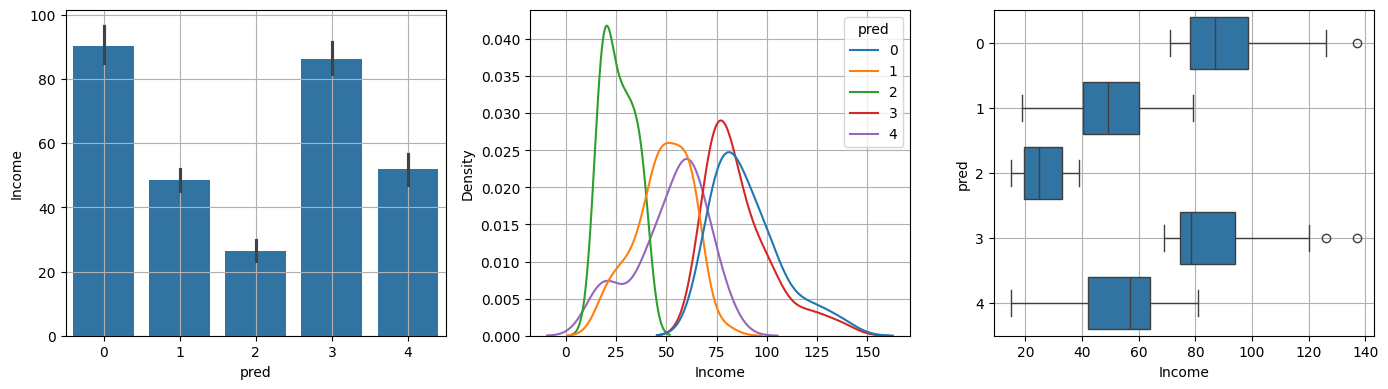
(3) Score
var = 'Score'
var_analysis(var)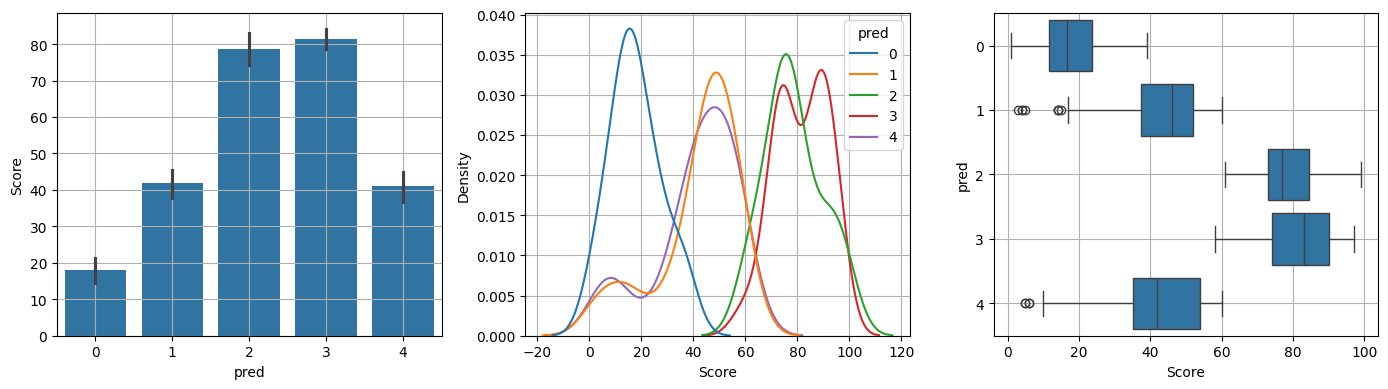
(4) Gender
- 모자익 플롯을 사용
from statsmodels.graphics.mosaicplot import mosaic
mosaic(result, ['pred','Gender'])
plt.show()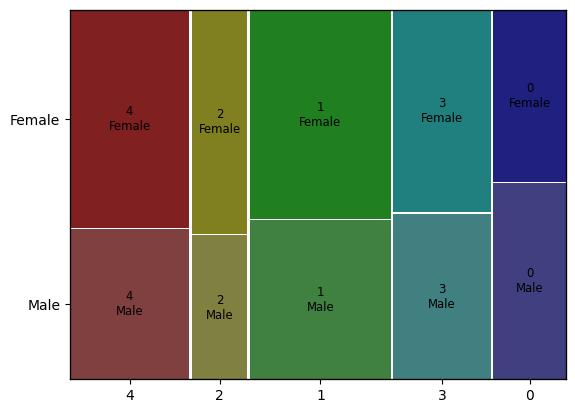
5. 한꺼번에 비교하기
- sns.pairplot을 이용하여 한꺼번에 비교
cols = ['Age', 'Income', 'Score', 'pred']
temp = result.loc[:, cols]
sns.pairplot(temp, hue = 'pred')
plt.show()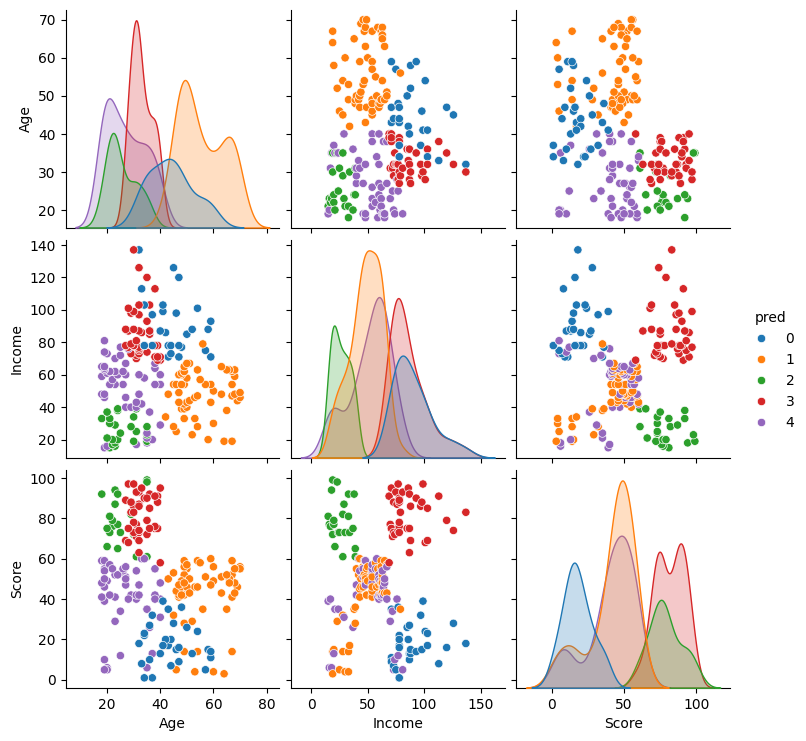
6. 각 군집별 특징
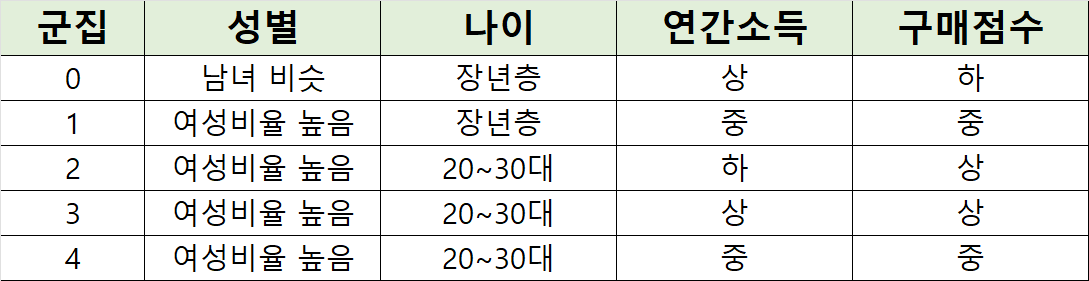
이런 식으로 각 군집별 특징을 분석해 고객별 특징을 분석하고 마케팅 전략을 수립할 수 있다.
(1) 군집 0
- 차별점: 소득은 높은데 구매 점수가 낮음(소극적 소비 성향)
- 마케팅 전략: 1:1 맞춤 전략
(2) 군집 1
- 차별점: 장년층 여성층, 안정적 소비
- 마케팅 전략: 건강 밀착형 제품
(3) 군집 2
- 차별점: 소득은 낮은데 구매 점수 높음, 충동/트렌드 소비 가능
- 마케팅 전략: sns 마케팅, 한정판 상품, 할인/프로모션 상품
(4) 군집 3
- 차별점: 젊고 소득 높음, 소비 적극적
- 마케팅 전략: 프리미엄 라인, VIP 관리
(5) 군집 4
- 차별점: 평균적인 소비 패턴
- 마케팅 전략: 가성비 상품, 적립
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 15주차 (0) | 2026.02.12 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 14주차 (0) | 2026.02.02 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 13주차 (0) | 2026.01.28 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 12주차 (1) | 2026.01.27 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 11주차 (0) | 2026.01.15 |