
🍀 앙상블 알고리즘 - Bagging
앙상블 알고리즘
- 여러 개의 머신러닝 모델을 조합해 하나의 강력한 예측 모델을 만드는 기법
- 각 모델이 가진 편향(Bias)와 분산(Variance)을 줄이고 일반화 성능을 개선
- 종류
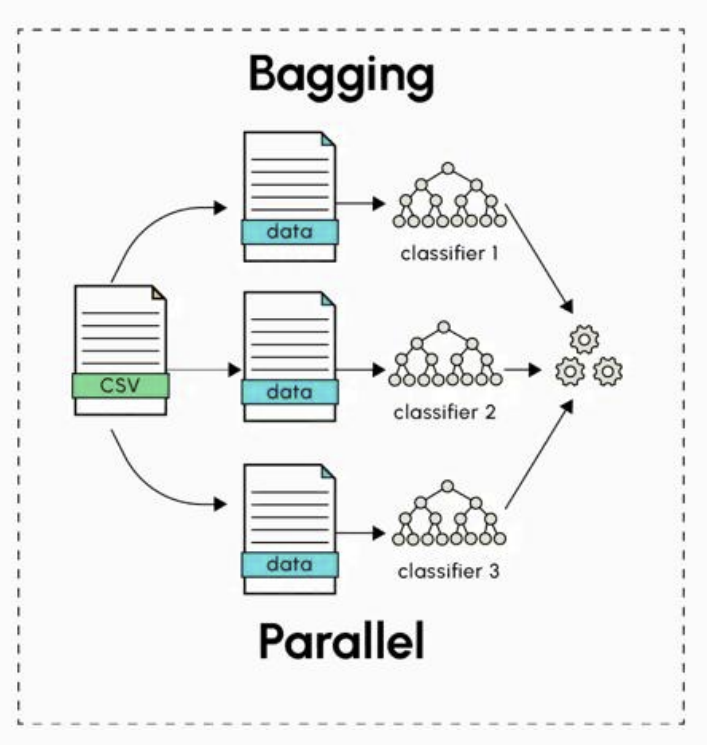
- Bagging: 여러 개의 동일한 모델(혹은 learner)를 서로 다른 데이터 샘플로 병렬 학습 후 예측 결과를 평균/투표로 결합
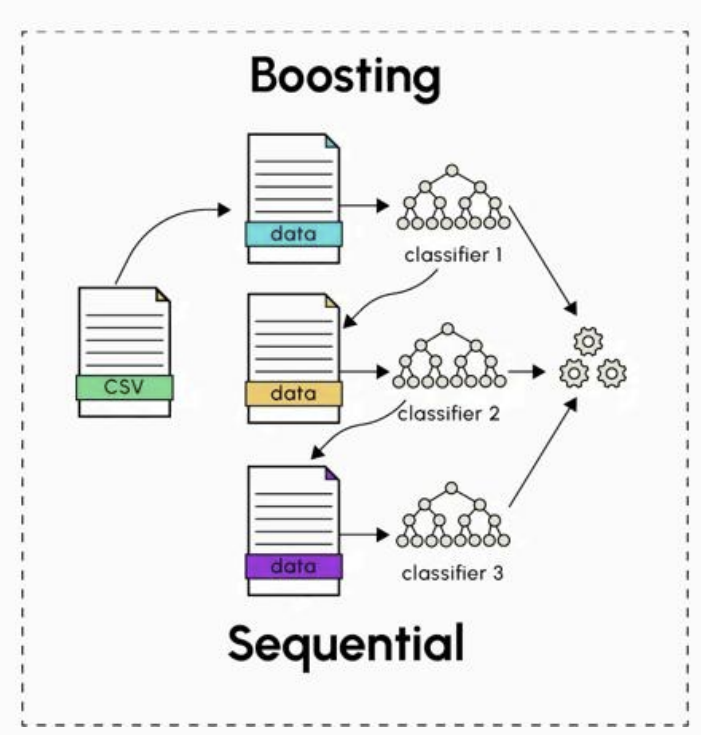
- Boosting: 모델을 순차적으로 학습. 이전 모델이 틀린 예측에 가중치를 주어 다음 모델이 보완하도록 학습하며, 최종 예측은 모두 합쳐서 결정
- Stacking: 여러 다양한 베이스 모델의 예측을 모아, 또 다른 메타 모델(meta learner)이 학습해 최종 예측을 수행
Bagging vs. Boosting
Bagging
- 병렬 구조(parallel)
- 동일한 모델을 사용하되, 서로 다른 데이터 샘플로 학습
- 각 모델이 독립적으로 병렬 학습
- 결과를 평균/투표로 결합
- 주로 분산(Variance) 감소에 효과적
Boosting
- 순차 구조(sequential)
- 동일한 모델을 반복적으로 학습
- 이전 모델의 예측 오류를 보완하는 방향으로 다음 모델을 생성
- 주로 편향(Bias) 감소에 효과적
| Bagging | Boosting |
|---|---|
 |
 |
Bagging
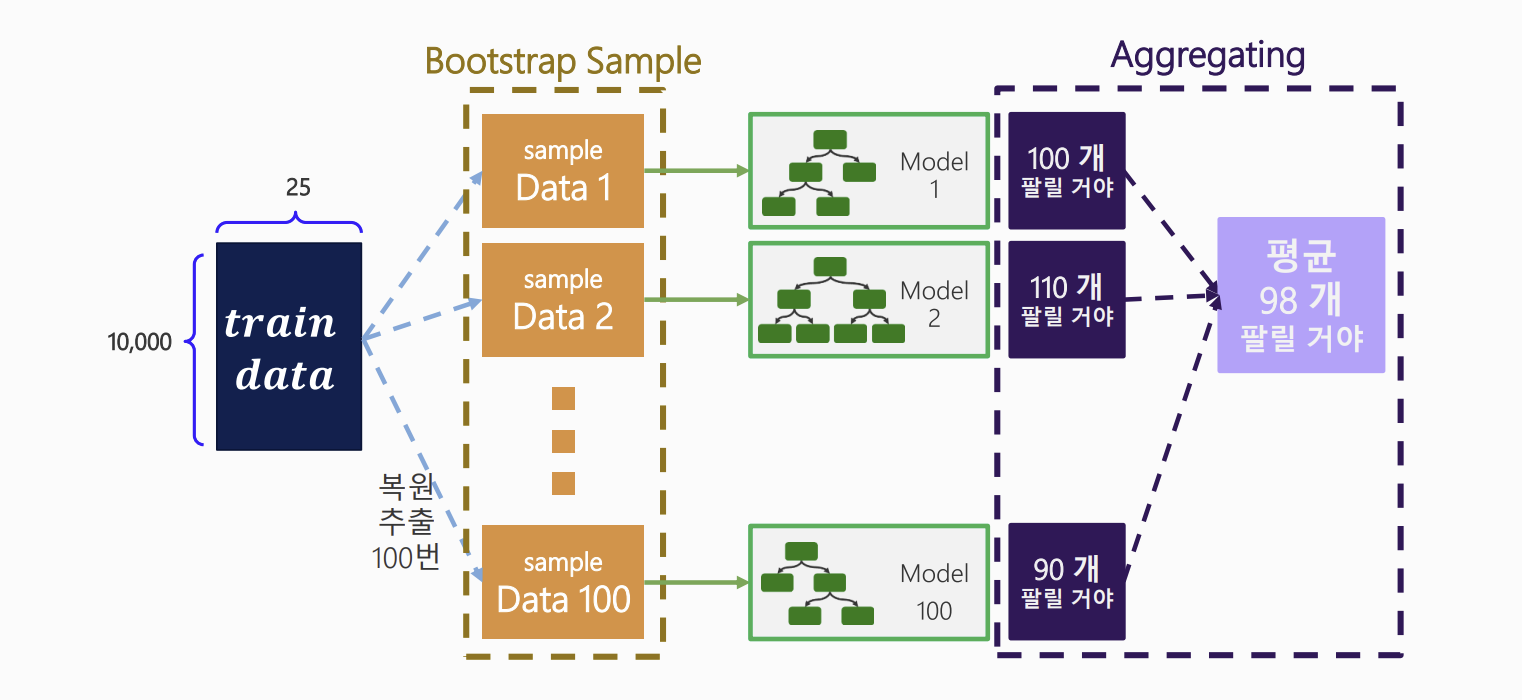
1. Bootstrap 샘플링 (데이터 샘플 생성)
- 전체 학습 데이터셋에서 복원 추출 방식으로 여러 개의 서브 데이터셋을 생성
- 각 서브 데이터셋의 크기는 보통 원본 데이터와 같거나 일부 비율로 설정
- 복원 추출이므로 하나의 데이터셋 내에서는 중복된 샘플이 포함될 수 있음
- 예시
- 원본 데이터: 10,000건
- 각 모델 학습용 데이터: 7,000건
- 이러한 샘플링을 100회 반복하여 100개의 서로 다은 학습 데이터셋 생성
2. 개별 모델 학습
- 각 Bootstrap 샘플마다 동일한 알고리즘의 모델을 학습
- 모델들은 서로 독립적 & 병렬적으로 학습
3. Aggregating (에측 결과 결합)
- 학습이 완료된 모든 모델의 예측 결과를 결합하여 최종 예측 생성
- 회귀(Regression): 각 모델의 예측값을 평균
- 분류(Classification): 각 클래스에 대한 다수결 투표
- 이 과정에서 안정적이고 일반화 성능이 높은 예측 결과를 얻게 됨
Random Forest
Random Forest이란, Bagging 기반의 앙상블 기법으로 데이터 샘플링뿐 아니라 특성(Feature) 선택에도 무작위성을 추가하여 모델 간 상관성을 낮춘 방법이다.
1. 행(Row)에 대한 랜덤성 - 데이터 샘플링
- 전체 학습 데이터에서 복원 추출(Bootstrap)로 여럭 개의 서브 데이터셋 생성
- 각 데이터셋으로 하나의 결정 트리 학습
2. Feature에 대한 랜덤성 - 분할 기준 선택
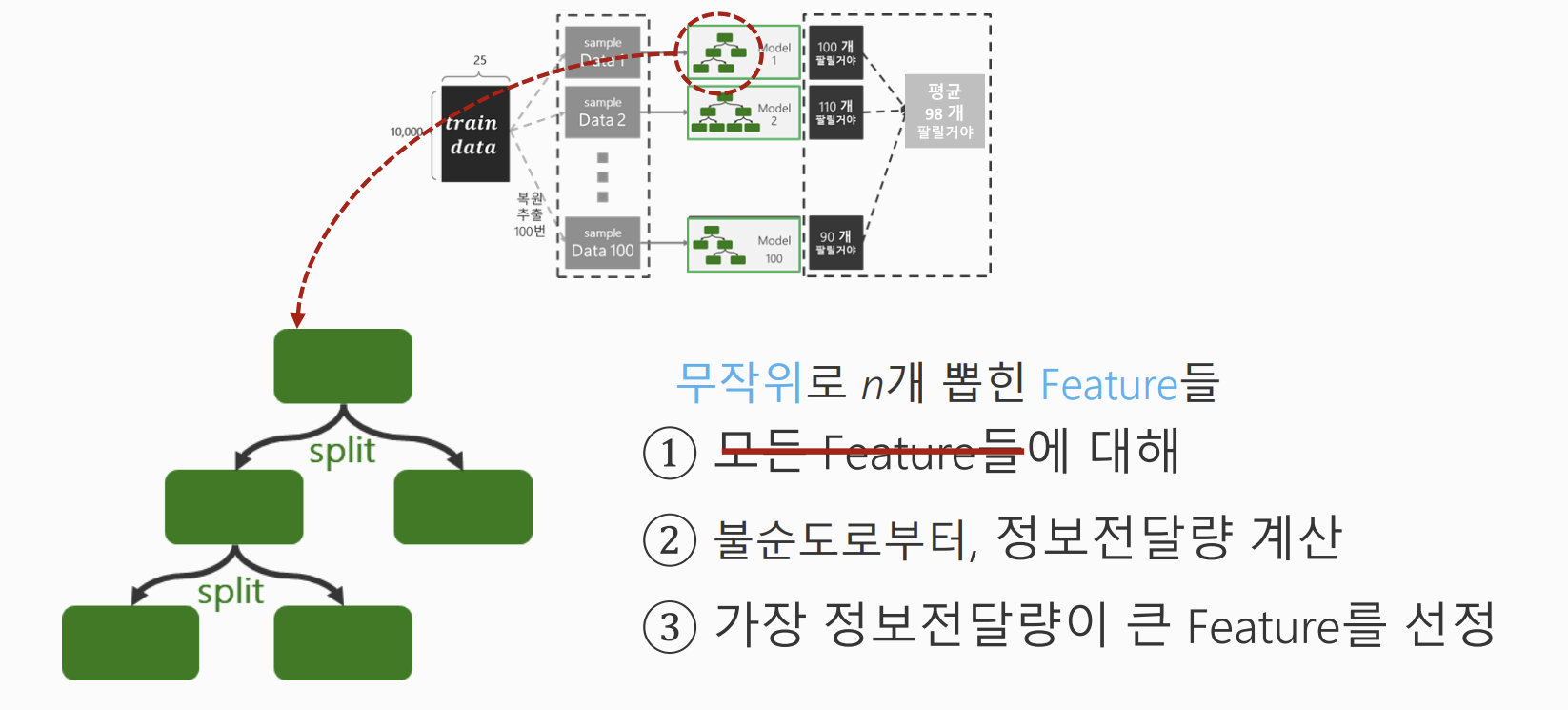
- 각 트리 노르 분할(split) 시, 전체 feature가 아닌 무작위로 선택된 일부 feature 중에서만 분할 기준을 탐색
- Decision Tree와 차이점
- Decision Tree: 모든 feature들에 대해 불순도로부터 정보전달량을 계산
- Random Forest: 무작위로 선택된 n개의 Feature들에 대해서만 불순도를 계산
- 정보전달량(Information Gain): 분할 이후 불순도가 얼마나 감소했는지 나타내는 지표
- 그중 불순도 감소가 가장 큰 feature를 분할 기준으로 선택
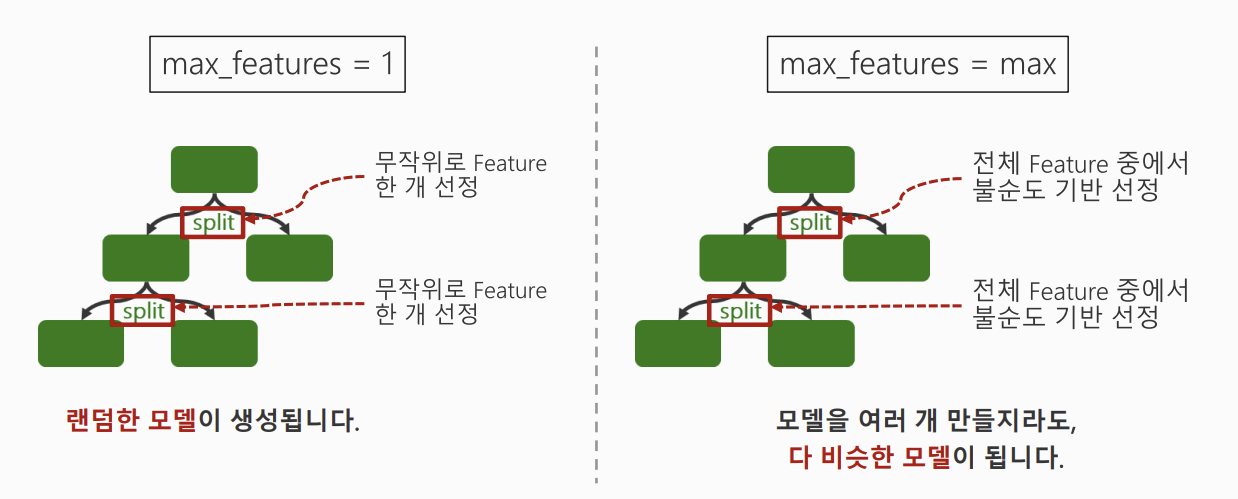
3. max_feature 설정의 의미
max_feature=1: 랜덤한 모델이 생성 → 트리 간 차이가 너무 커져 예측이 불안정해질 수 있음max_feature=max: 전체 모델에서 랜덤하게 뽑기 때문에 다 비슷한 모델이 생성됨 → random Forest 만든 이유가 없어짐
** → 따라서 일정 범위 내의 feature 수를 랜덤 선택하는 것이 핵심**
- 일반적인 기본값(default)
- 분류:
√(전체 feature 수) - e.g. feature가 25개 → max_feature = 5
- 보통 default로 하면 안정적인 성능을 보임
- 분류:
Random Forest 함수
함수
- 분류: sklearn.ensemble.RandomForestClassifier
- 회귀: sklearn.ensemble.RandomForestRegressor
hyper parameter
- n_estimators: 트리의 개수 (보통 100)
- max_feature: split 대상 feature의 개수
- auto: sqrt(전체 feature)의 수
- 숫자
- oob_score=True : 학습할 때 validation 수행
🍀 앙상블 Bagging 모델링 실습
1. 데이터 준비
(1) 데이터 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split(2) 데이터 업로드
# mobile data
path = "https://raw.@@@.csv"
data = pd.read_csv(path)
data.drop(['id', 'REPORTED_USAGE_LEVEL','OVER_15MINS_CALLS_PER_MONTH'], axis = 1, inplace = True)
data.rename(columns = {'HANDSET_PRICE':'H_PRICE',
'AVERAGE_CALL_DURATION':'DURATION',
'REPORTED_SATISFACTION':'SATISFACTION',
'CONSIDERING_CHANGE_OF_PLAN':'CHANGE'}
, inplace = True)
data.head()(3) 가변수화
# 데이터분할1
target = 'CHURN'
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 가변수화
dumm_cols = ['SATISFACTION','CHANGE']
x = pd.get_dummies(x, columns = dumm_cols, drop_first = True)
# 데이터 분할2
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.5)
# test_size=0.5인 이유: 모델링 시간 줄이려고 2. 모델링
(1) 함수 불러오기
from sklearn.tree import plot_tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import *
# shape 알아보기
x_train.shape # (10000, 15)
# max_feature = sqrt(15) = 3.xx(2) 모델 선언
# 2) 모델 선언
model = RandomForestClassifier(n_estimators = 5, max_depth = 3)(3) 학습
model.fit(x_train, y_train)(4) 예측 및 평가
# 예측
pred = model.predict(x_val)
# 평가
print(classification_report(y_val, pred))# 결과
precision recall f1-score support
LEAVE 0.72 0.61 0.66 4933
STAY 0.67 0.77 0.72 5067
accuracy 0.69 10000
macro avg 0.70 0.69 0.69 10000
weighted avg 0.70 0.69 0.69 10000
3. Random Forest
(1) 모델 내부 살펴보기
# 5개 decision tree
# 앙상블 모델에 포함된 개별 Decision Tree 객체들의 리스트
model.estimators_
# 학습된 여러 개의 Decision Tree 중 개별 모델 하나를 확인하고 싶을 때
model.estimators_[1]# 각 트리별로 시각화 할 수 있다.
plt.figure(figsize=(15,6))
plot_tree(model.estimators_[0],
feature_names = x_train.columns,
class_names= ['LEAVE','STAY'],
filled = True, fontsize = 8);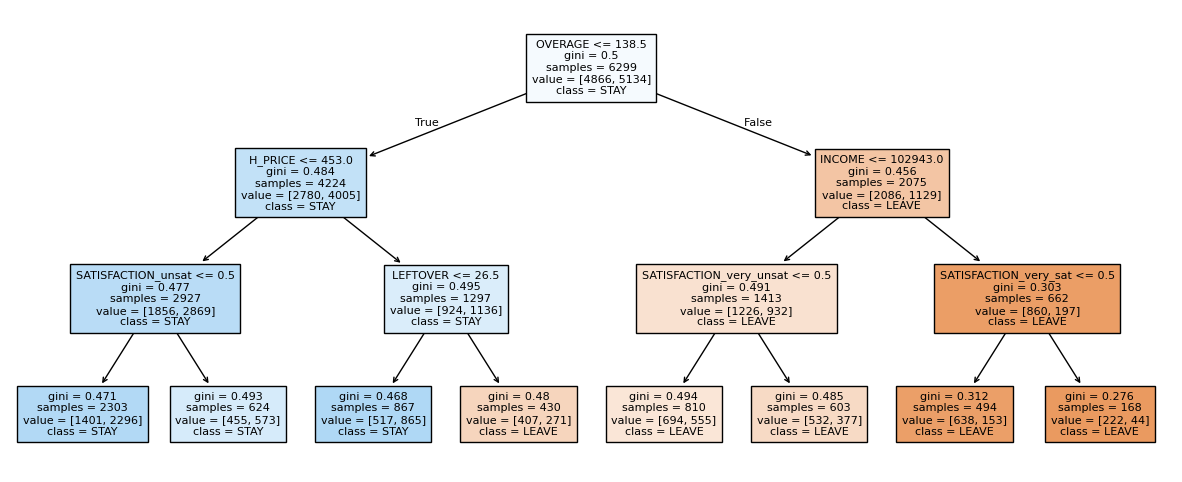
(2) 변수 중요도
print(x_train.columns)
print(model.feature_importances_)- 변수중요도 그래프 그리기 함수 만들기
def plot_feature_importance(importance, names):
feature_importance = np.array(importance)
feature_names = np.array(names)
data={'feature_names':feature_names,'feature_importance':feature_importance}
fi_df = pd.DataFrame(data)
fi_df.sort_values(by=['feature_importance'], ascending=False,inplace=True)
fi_df.reset_index(drop=True, inplace = True)
plt.figure(figsize=(10,8))
sns.barplot(x='feature_importance', y='feature_names', data = fi_df)
plt.xlabel('FEATURE IMPORTANCE')
plt.ylabel('FEATURE NAMES')
plt.grid()plot_feature_importance(model.feature_importances_, x_train.columns)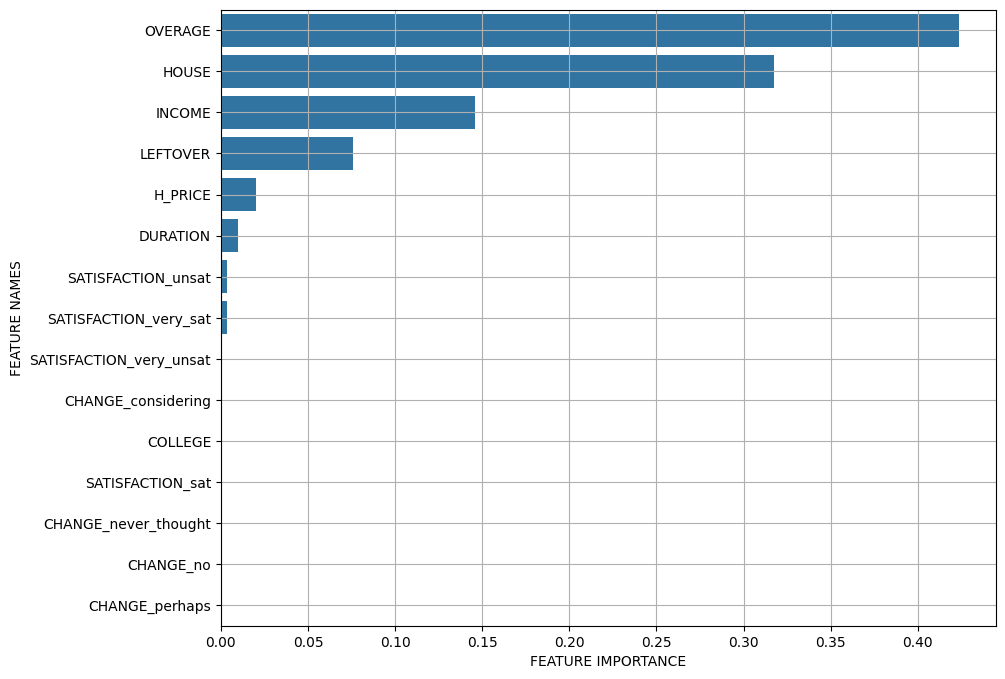
4. Random Forest 튜닝
(1) 하이퍼파라미터 설정
params = {'n_estimators': range(5,101,5), 'max_depth':[3,5,7,9]}(2) 모델 선언 및 학습
# 함수 불러오기
from sklearn.model_selection import GridSearchCV
# 모델 선언 및 학습
model_gs = GridSearchCV(RandomForestClassifier(), params, cv = 5)
model_gs.fit(x_train, y_train)(3) 튜닝 결과 확인
# 튜닝 결과 확인
model_gs.best_params_, model_gs.best_score_({'max_depth': 9, 'n_estimators': 100}, np.float64(0.7071999999999999))(4) 튜닝된 모델로 예측하고 평가하기
# 튜닝된 모델로 예측하고 평가하기
pred = model_gs.predict(x_val)
print(classification_report(y_val, pred))(5) 튜닝 결과 확인 - 그래프로 확인하기
# 튜닝 결과 확인2 : 그래프로 확인하기
result = pd.DataFrame(model_gs.cv_results_)
result = result[['param_max_depth','param_n_estimators', 'mean_test_score']]
plt.figure(figsize = (10,6))
sns.lineplot(x = 'param_n_estimators', y = 'mean_test_score', data = result
, hue = 'param_max_depth' )
plt.grid()
plt.show()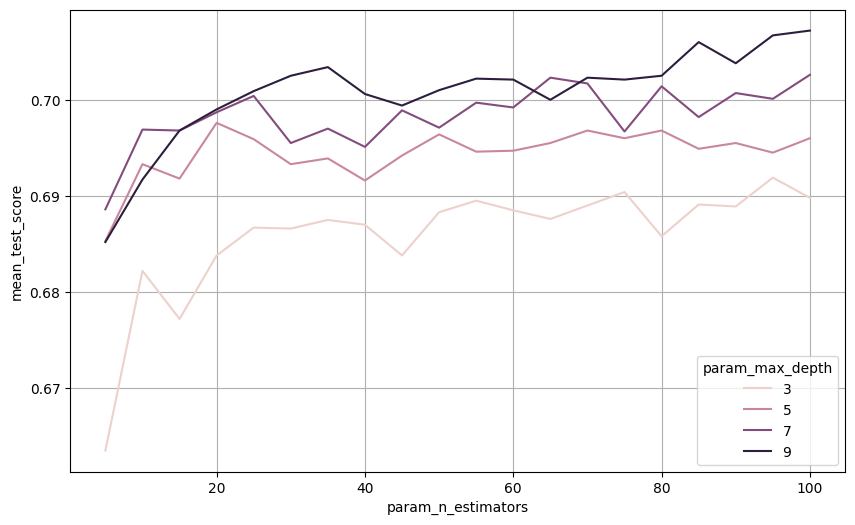
model_gs.best_estimator_.feature_importances_
# 변수 중요도
plot_feature_importance(model_gs.best_estimator_.feature_importances_, x_train.columns)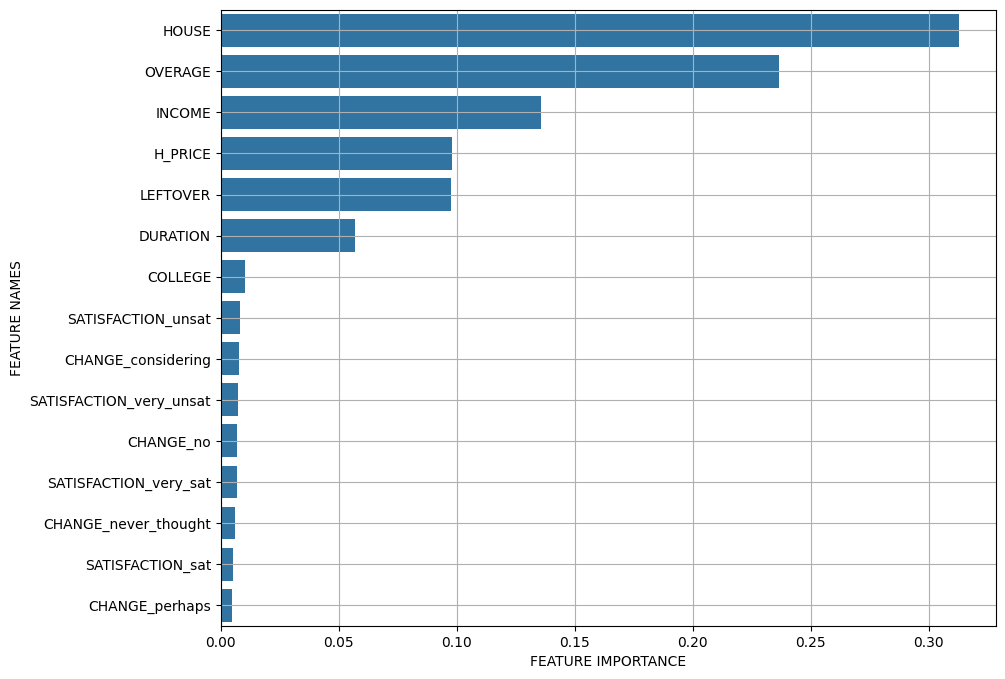
🍀 BDA 블로그 챌린지
BDAI에서 12기 학회원을 모집한다고 합니다!!
11기로 활동하면서 배운 것도 많고 학회가 체계적이라서 정말 만족했습니다.
아래에 링크 첨부했으니 많은 관심 부탁드립니다~🤗
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 13주차 (0) | 2026.01.28 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 12주차 (1) | 2026.01.27 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 모델링 실습 (0) | 2026.01.06 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 (0) | 2026.01.05 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 9주차 (0) | 2026.01.04 |