🌀 SVM
1. SVM (Support Vector Machine)
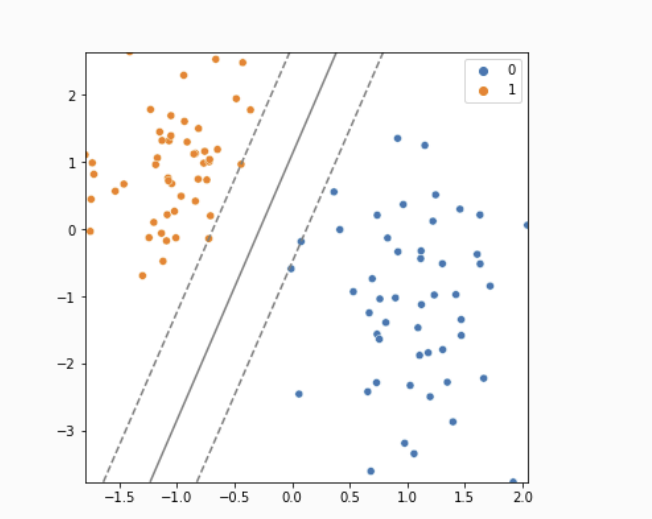
- 두 클래스가 존재한다고 가정
- e.g. 0(파란색 클래스)와 1(주황색 클래스)
- SVM의 핵심 아이디어: 두 클래스 사이에 가장 넓은 도로를 내는 것
- 즉, 두 클래스 사이의 가장 넓은 도로를 찾고 그 가운데 중앙선을 모델이라고 함.
- 분류와 회귀에서 모두 사용 가능
중요한 용어 정리
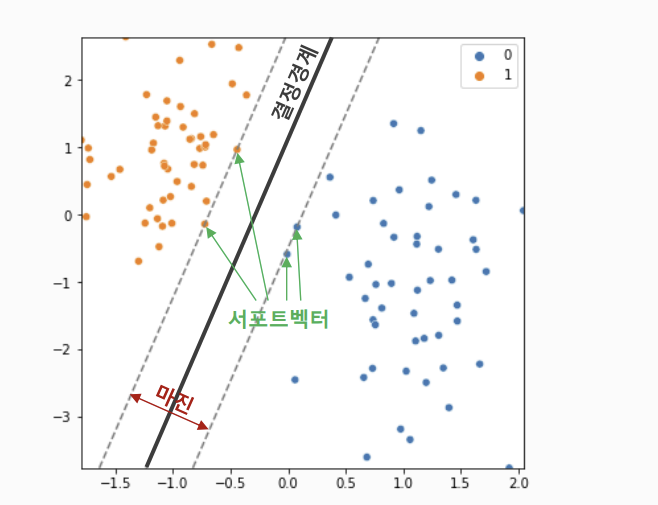
결정 경계(Decision Boundary)
- 클래스를 구분하는 경계선, 도로의 중앙선
- SVM에서 결정 경계가 바로 모델!
- 수학적으로는 초평면(hyper plane)이라고 부름
백터(Vector)
- 모든 데이터 포인트
- 각각의 관측치(샘플)를 의미
서포트 벡터(Support Vector)
- 결정 경계와 가장 가까운 데이터 포인트
- 도로의 가장자리에 놓인 점들
- 특징
- 전체 데이터 중 일부만 모델을 결정
- 이 점들이 이동하면 결정 경계와 마진도 함께 변함
마진(Margin)
- 서포트벡터와 결정경계 사이의 거리. 도로의 폭.
- SVM의 목표: 폭이 가장 넓은 도로를 뚫는 것 (= 마진 최대화)
- 마진이 클 수록 새로운 데이터에 대해 안정적 분류가 가능
결정 경계(Decision Boundary)와 마진
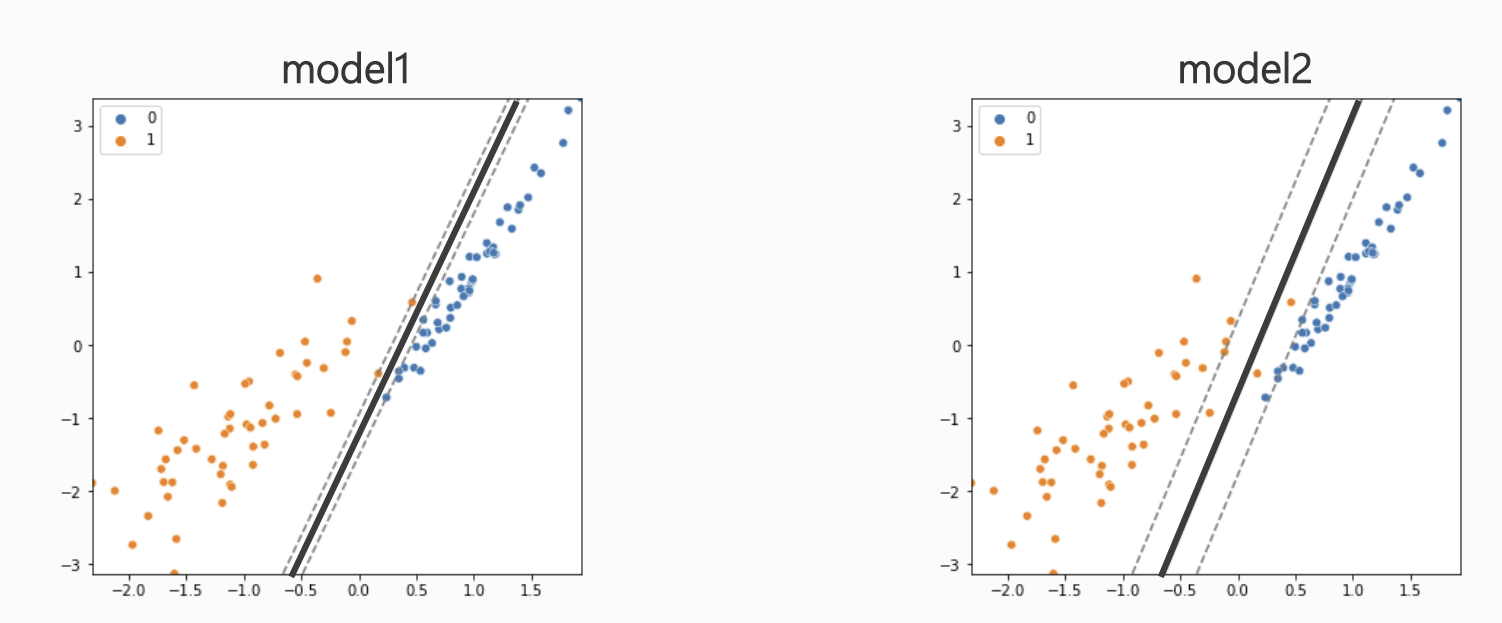
model1
- 모델은 하나의 오차도 허용하지 않고 완벽히 분류
- But, 마진이 매우 좁음
- 파란색 클래스 데이터가 조금만 벗어나도 잘못 분류될 가능성이 큼 → 일반화 성능 ↓
model2
- 주황색 클래스에 대해 일부 오차(2개)를 허용
- 마진이 넓음
- 기존 데이터에서 조금 벗어나도 안정적으로 분류 가능 → 일반화 성능 우수
2. 비용(C)
마진과 오류
- 마진(도로의 폭)은 가능한 넓게 & 오류는 가능한 적게
- 마진의 크기와 오류에 대한 허용 정도는 Trade-off
- 조절할 수 있는 것: 비용(C)
C 값을 높이면
- 오류를 허용하지 않으려는 비용 증가
- 결과적으로 훈련 데이터에 최대한 맞춘 결정 경계 선택
- 마진이 좁하질 가능성 증가
- 특징:
- 학습 데이터 성능 ↑
- 테스트 데이터 성능 ↓ 가능
- ➔ Overfitting 가능성 높아짐
C 값을 낮추면
- 오류를 허용하는 비용 감소
- 일부 오차를 감수하고 마진이 넓은 결정 경계 선택
- 특징
- 학습 데이터 성능 ↓
- 테스트 데이터에서 안정적인 성능 가능
- ➔ Underfitting 가능성 높아짐
🌀 SVM 실습
(1) import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons, make_classification
from sklearn.svm import SVC
import warnings # 경고메시지 제외
warnings.filterwarnings(action='ignore')(2) svm 모델을 시각화 하는 함수 만들기
def svm_visualize(x, y, model, title = "") :
xx, yy = np.meshgrid(np.linspace(x[:,0].min(), x[:,0].max(), 50),
np.linspace(x[:,1].min(), x[:,1].max(), 50)) # mesh grid
# 메쉬 그리드값에 대해 모델 부터 거리 값 만들기.
Z = model.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 그래프 그리기
plt.figure(figsize=(4, 4))
# 데이터 산점도
sns.scatterplot(x=x[:,0], y=x[:,1], hue=y)
# levels= 0 모델 , -1, 1 은 마진 경계
plt.contour(xx, yy, Z, levels=[-1, 0, 1], colors = 'gray',linestyles = ['--','-','--'])
plt.title(title)
plt.axis("tight")
plt.show()(3) 샘플 데이터 생성
seed = 8
x, y = make_classification(n_samples=100,
n_features=2,
n_redundant=0,
weights = [0.5, 0.5], # class 0과 1의 비율 조정 ==> class imbalance 상황만들기
n_clusters_per_class=1,
random_state=seed)
sns.scatterplot(x=x[:,0],y=x[:,1], hue = y)
plt.show()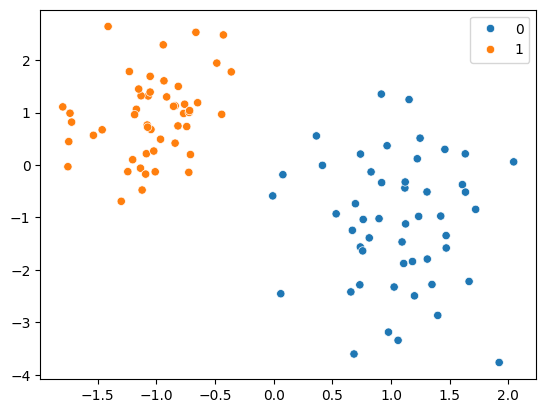
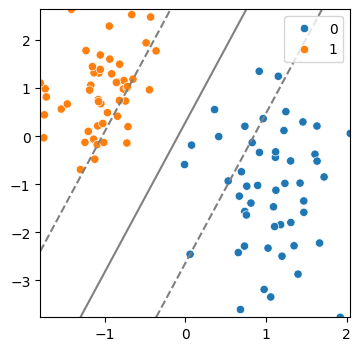
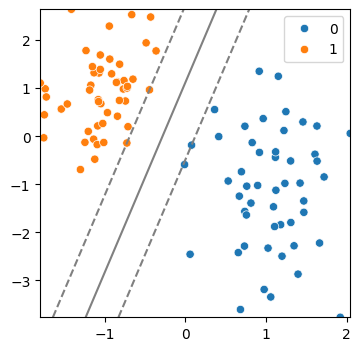
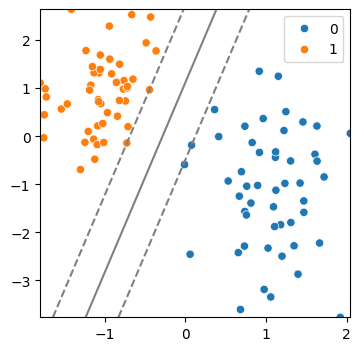
(4) SVM 모델 생성 및 시각화
model = SVC(kernel = 'linear', C = 10)
model.fit(x,y)
svm_visualize(x, y, model)| C=0.1 | C=10 | C=50 |
|---|---|---|
 |
 |
 |
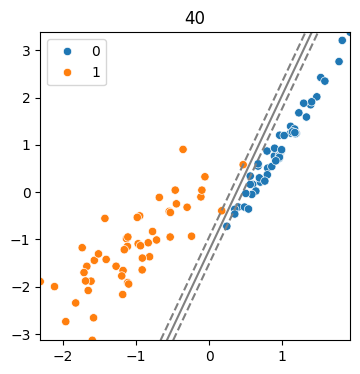
(5) 결정 경계와 마진
seed = 34
x, y = make_classification(n_features=2, n_redundant=0, weights = [0.5, 0.5],
n_clusters_per_class=1, random_state=seed)
sns.scatterplot(x=x[:,0],y=x[:,1], hue = y)
plt.show()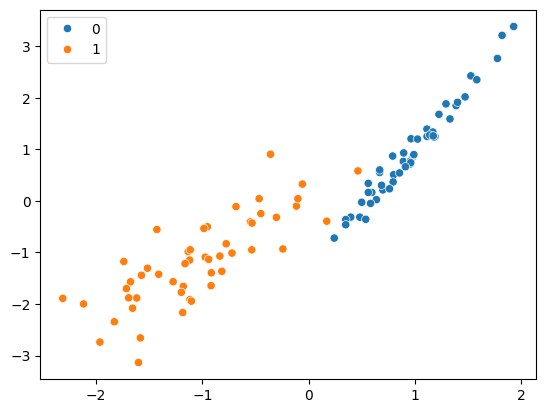
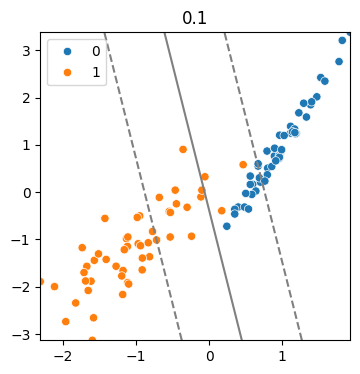
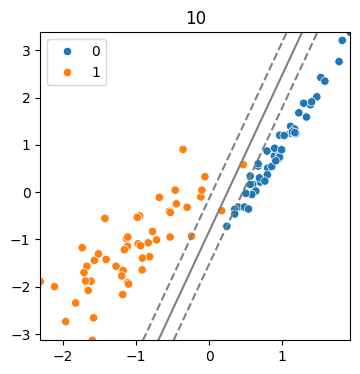
(6) cost 값에 따른 모델
cost = 40
model = SVC(kernel = 'linear', C = cost)
model.fit(x,y)
svm_visualize(x, y, model, cost)| C=0.1 | C=10 | C=40 |
|---|---|---|
 |
 |
 |
🌀 비선형 SVM
1. 커널 트릭(Kernel Trick)
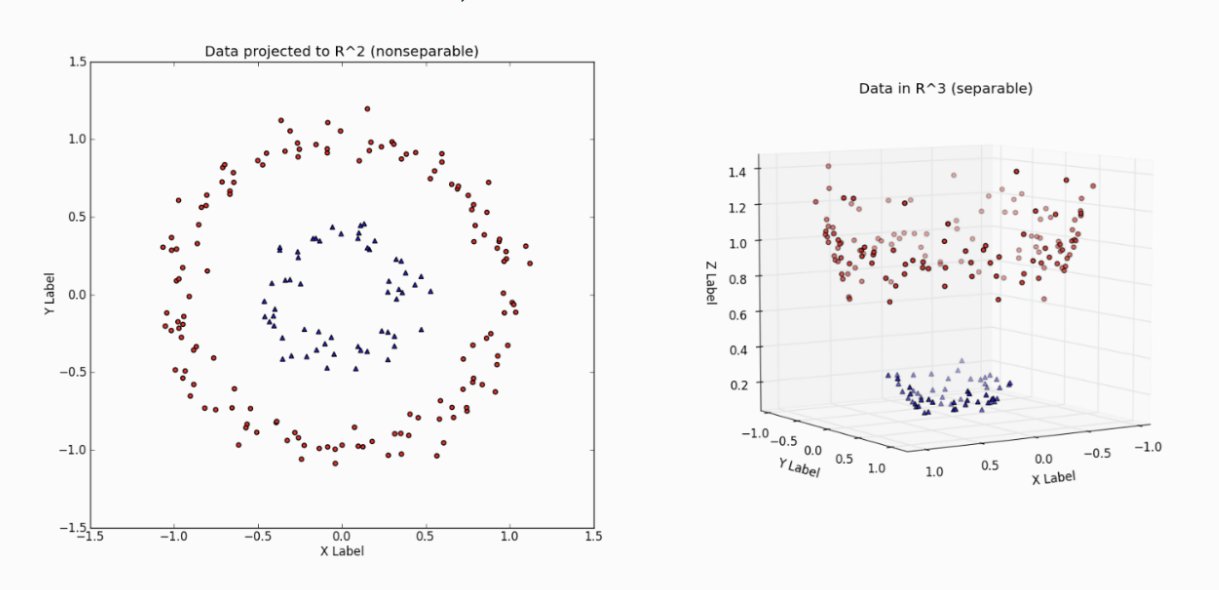
매핑 함수
- 비선형 데이터 문제를 해결하기 위해
- 저차원 공간의 데이터를 고차원 데이터로 변환하는 함수
- 원래 구분되지 않던 데이터가 선형 분리 가능해질 수 있음
- 문제점: feature수가 과도하게 증가하여 연산 시간이 엄청나게 길어짐 → 계산 비용 커짐
커널 트릭
- 실제 고차원 feature를 생성하지 않음
- 대신, 고차원 공간에서의 내적 결과만 계산
- → 고차원 feature를 확장한 것과 동일한 효과
2. 커널 종류
poly(Polynomial Kernel)
- 다차항(polynomial) 커널
- 입력 변수들 조합을 통해 곡선 형태 결정 경계 생성
- 주요 하이퍼파라미터 : degree(차수), coef0(다차항 별 영향도 조절), C (오차 비용),
gamma(결정경계 복잡도)
⭐rbf(Radial Basis Function)
- 보통 가우시안 커널이라고 부름. 가우시안분포(정규분포)를 이용
- 대부분 rbf를 많이 씀. SVM에서 default가 rbf임!
- 주요 하이퍼파라미터 : C (오차 비용), gamma(결정경계 복잡도)
sigmoid
- 시그모이드 함수 기반 커널
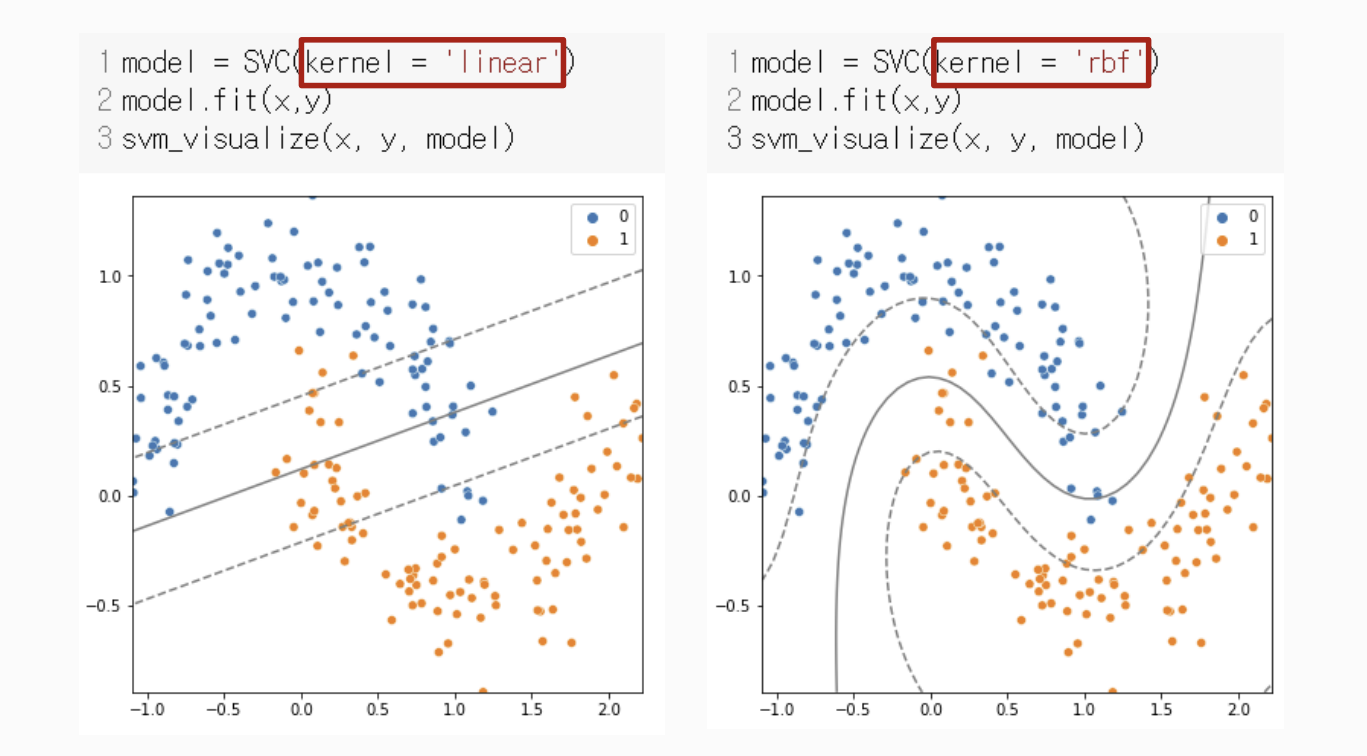
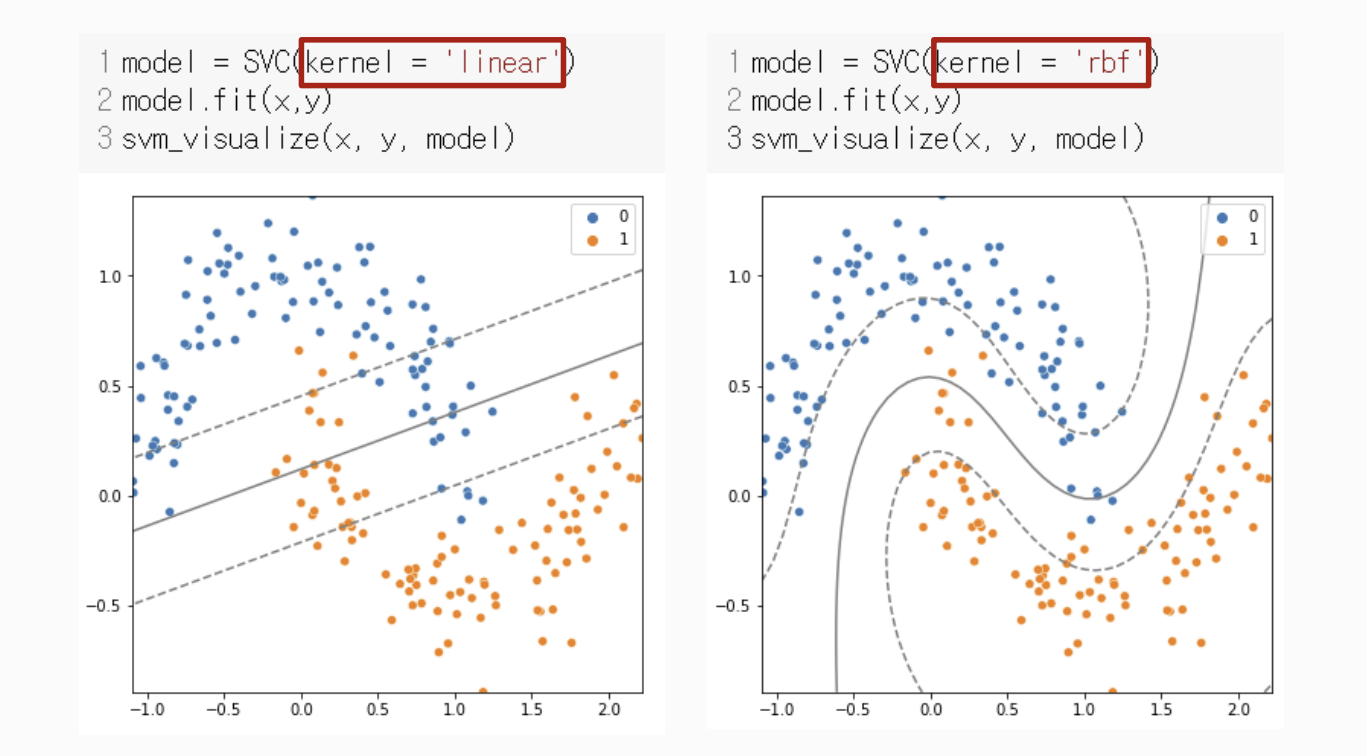
선형 SVM과 비선형 SVM 비교
3. 비선형 SVM에서의 Hyper Parameter
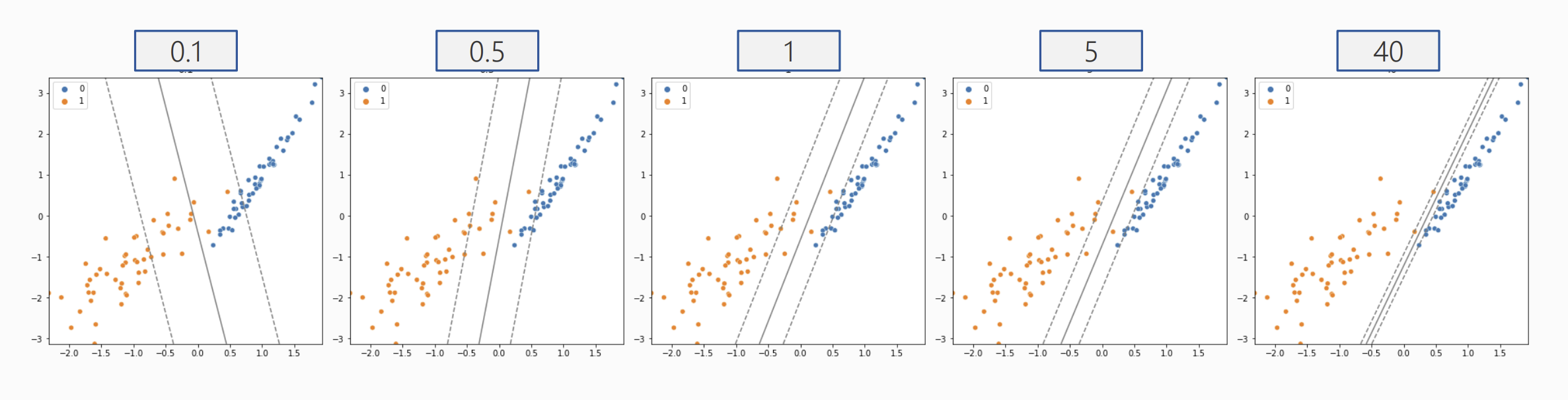
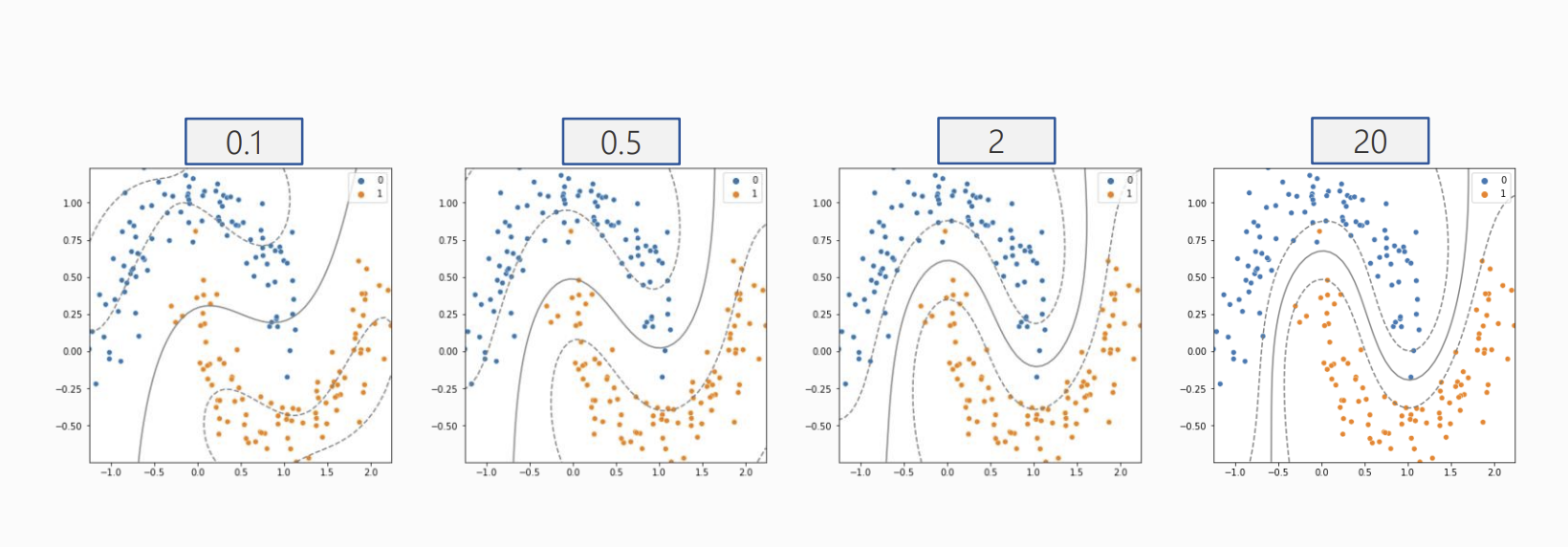
COST
- rbf 커널에서 Cost의 변화
- Cost가 증가할 수록 마진의 폭이 줄어들고, 오차를 줄이기 위한 모델이 생성
- 마진 폭이 줄어들 수록 모델이 복잡해짐.
Gamma
- 하나의 데이터 포인트가 결정 경계 형성에 영향을 미치는 범위를 의미
- 직관적으로 결정 경계의 곡률을 조절
- gamma 값이 클 수록
- 곡률 반경이 작아짐
- 결정 경계가 매우 세밀하고 복잡해짐
- Train Set에 잘 fitting 됨.
- But, 다른 데이터에서는 잘 안 맞을 가능성 증가 → 과적합 위험 증가
🌀 비선형 SVM 실습
(1) 데이터 생성 및 시각화
x, y = make_moons(n_samples = 200, noise = .13, random_state = 10)
plt.figure(figsize = (6,6))
sns.scatterplot(x=x[:,0], y=x[:,1], hue = y)
plt.show()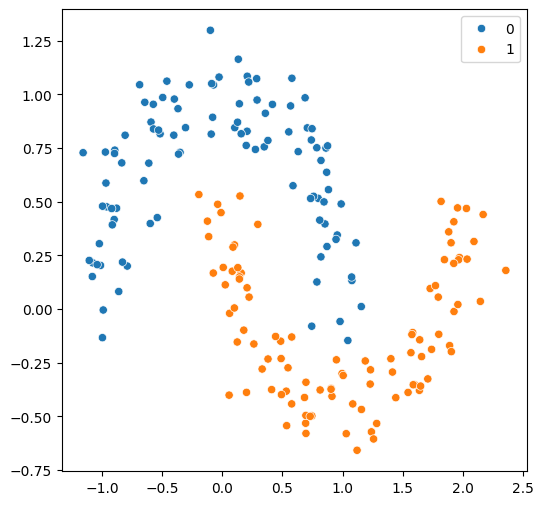
(2) 선형경계로 분류
model = SVC(kernel = 'linear')
model.fit(x,y)
svm_visualize(x, y, model)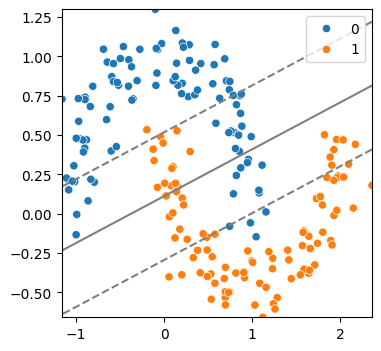
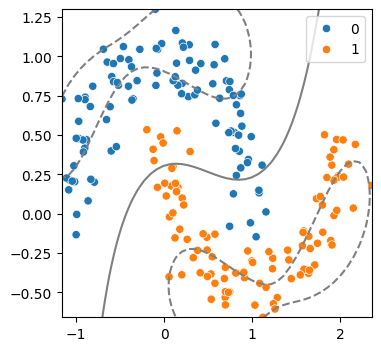
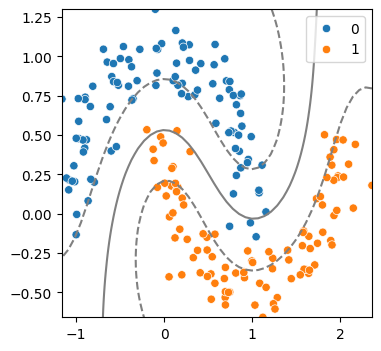
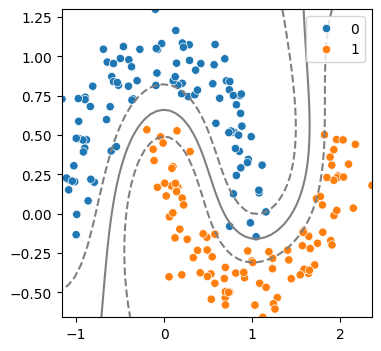
(3) 커널 트릭 사용: rbf
model = SVC(kernel = 'rbf', C = 1)
model.fit(x,y)
svm_visualize(x, y, model)| C=0.1 | C=1 | C=10 |
|---|---|---|
 |
 |
 |
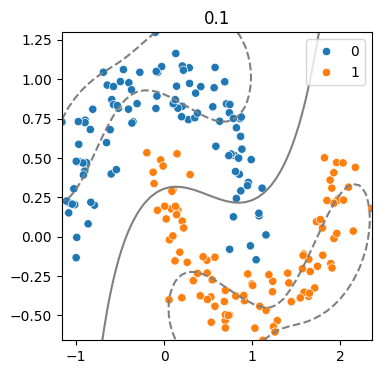
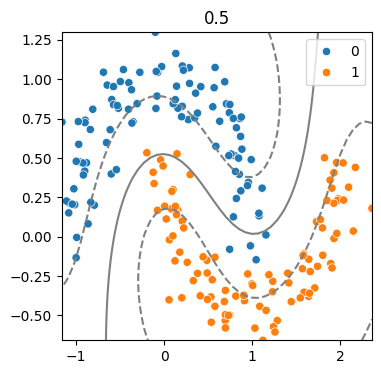
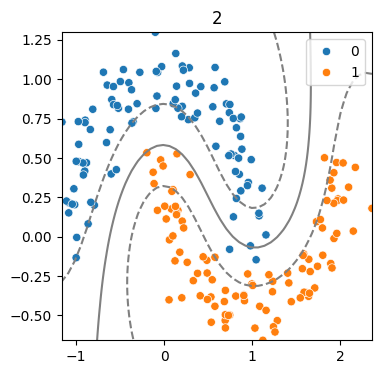
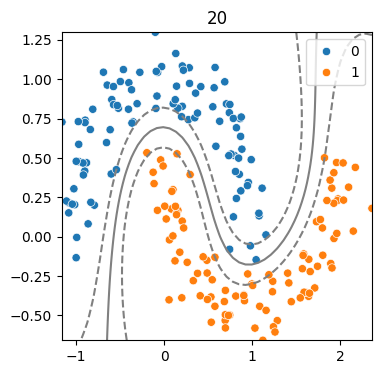
(4) 하이퍼파라미터 - Cost에 따른 결정경계 변화
for cost in [0.1, .5, 2, 20] :
model = SVC(kernel = 'rbf', C = cost)
model.fit(x,y)
svm_visualize(x, y, model, cost)| C=0.1 | C=0.5 | C=2 | C=20 |
|---|---|---|---|
 |
 |
 |
 |
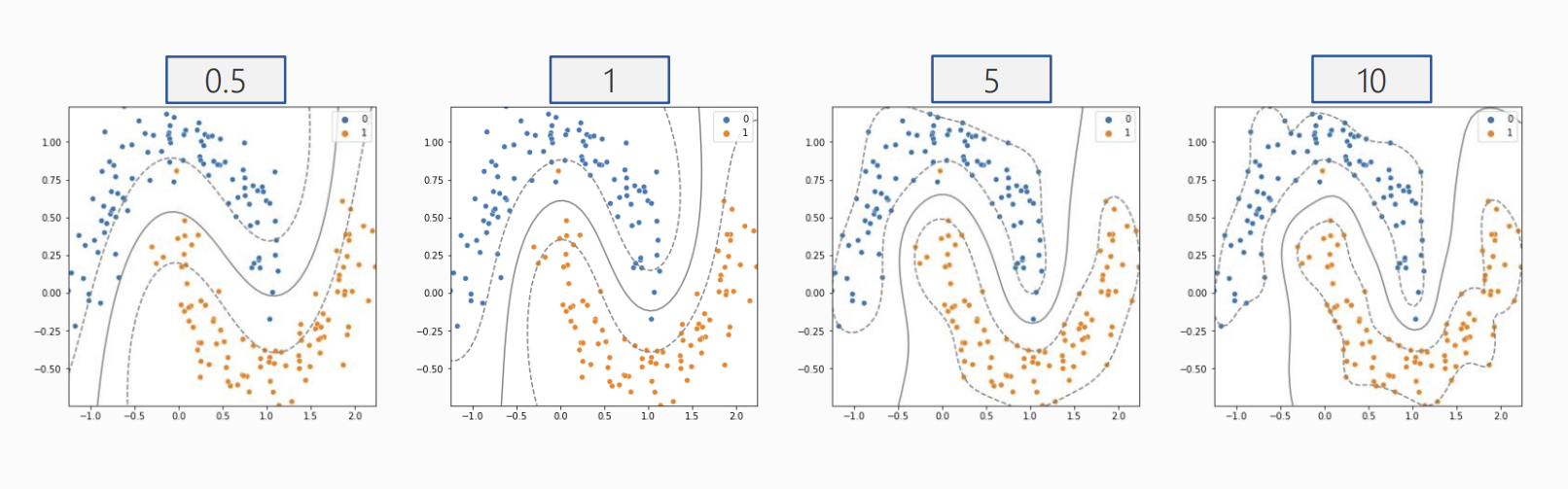
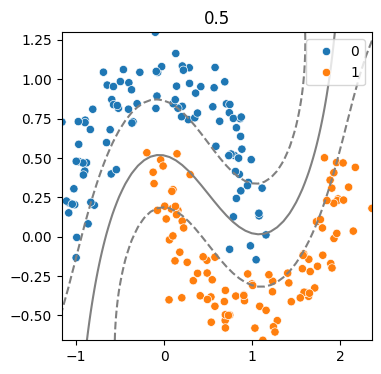
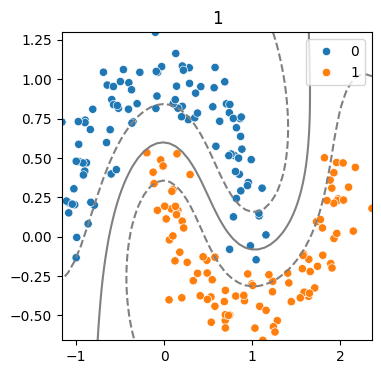
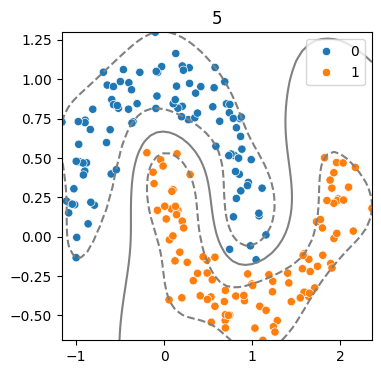
(5) 하이퍼파라미터 - Gamma 따른 결정경계 변화
for g in [.5, 1, 5, 10] :
model = SVC(kernel = 'rbf', C = 2, gamma = g)
model.fit(x,y)
svm_visualize(x, y, model, g)| C=0.5 | C=1 | C=5 | C=10 |
|---|---|---|---|
 |
 |
 |
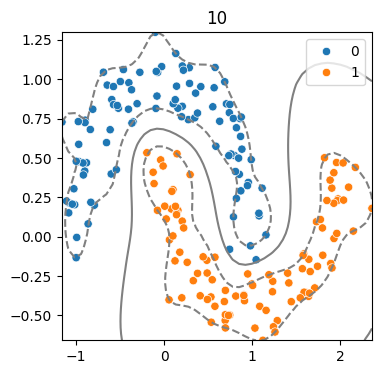 |
즉, Cost와 Gamma는 모델의 복잡도와 일반화 성능을 결정하는 핵심 하이퍼파라미터이므로,
튜닝을 통해 최적의 조합을 탐색해야 한다!
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 11주차 (0) | 2026.01.15 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 모델링 실습 (0) | 2026.01.06 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 9주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 8주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |