
🌱Decision Tree 개념
Decision Tree의 구조
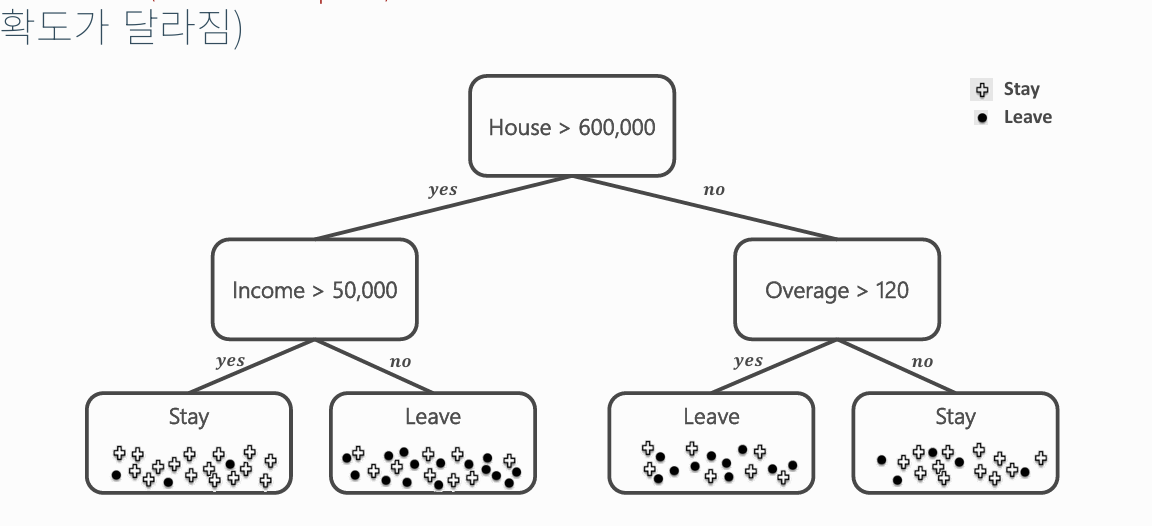
- *root node : *
- decision tree의 맨 위의 node
- 부모가 없는 노드, 트리에서 유일함
leaf node :
- decision tree에서 말단에 위치한 node
- 자식이 없음
간선(edge) : 노드를 연결하는 선 (link, branch 라고도 부름)
트리의 크기(max_depth): root node에서 leaf까지 도달하기 위해 거쳐야 하는 간선의 수
e.g. 위의 사진의 depth = 2
Tree 알고리즘이 제공하는 것들
변수 중요도 : 모델링 이후, 모델에서 중요한 변수를 수치화해서 제공함
모델링 중에서 유일함!
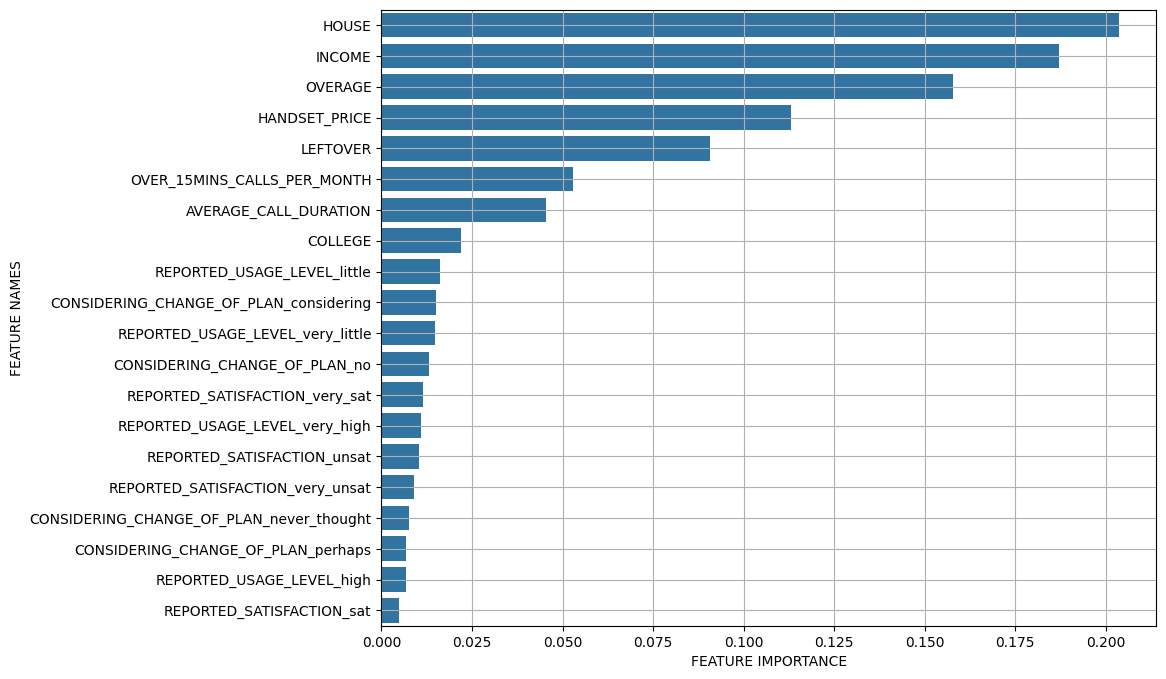
"AVERAGE_CALL_DURATION"와 " COLLEGE" 사이 급격하게 변하는 구간을 기준으로 중요도가 급격히 떨어짐 -> 상위 변수들이 모델에 더 큰 영향을 미친다고 볼 수 있음

- 모델 시각화 : 모델 구조를 시각화해줌
🌱Decision Tree 시각화 코드
모델 시각화
# 시각화에 필요한 라이브러리 불러오기
from sklearn.tree import plot_tree
plot_tree(model, # 만든 모델 이름 / 시각화할 모델 객체
feature_names = x_train.columns, #Feature 이름, list(x_train)
filled = True); # 각 노드를 클래스 비율에 따라 색으로 채움model2 = DecisionTreeClassifier(max_depth = 3) # 트리의 최대 깊이를 3으로 제한
model2.fit(x_train, y_train)
plt.figure(figsize = (20,6)) # 그림 사이즈 조절
plot_tree(model2, feature_names = x_train.columns,
filled = True, fontsize = 10) #노드 내 텍스트 크기 조절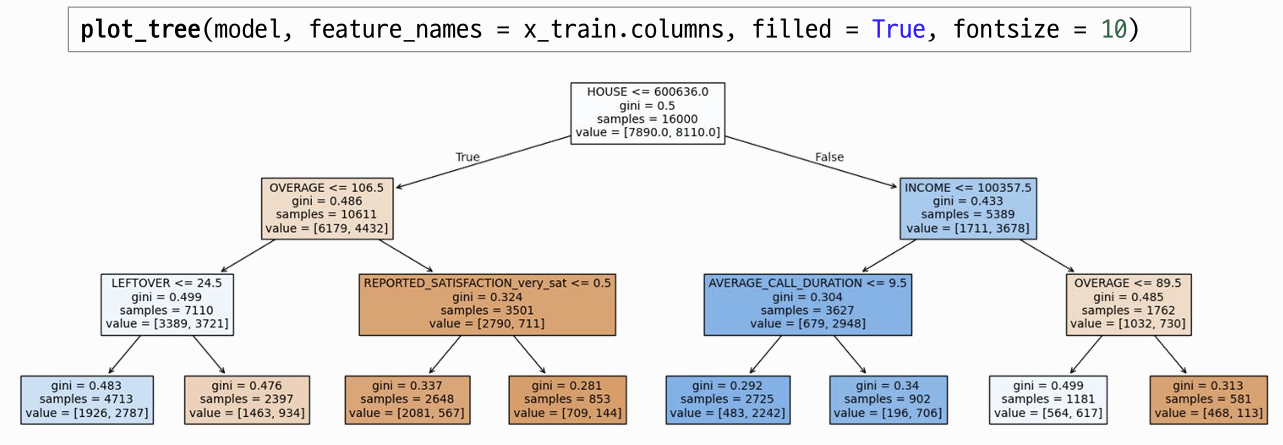
변수 중요도
# 변수 중요도
print(x_train.columns)
print(model.feature_importances_) # 각 변수의 중요도를 0~1 사이 값으로 반환 # 결과값
Index(['COLLEGE', 'INCOME', 'OVERAGE', 'LEFTOVER', 'HOUSE', 'HANDSET_PRICE',
'OVER_15MINS_CALLS_PER_MONTH', 'AVERAGE_CALL_DURATION',
'REPORTED_SATISFACTION_sat', 'REPORTED_SATISFACTION_unsat',
'REPORTED_SATISFACTION_very_sat', 'REPORTED_SATISFACTION_very_unsat',
'REPORTED_USAGE_LEVEL_high', 'REPORTED_USAGE_LEVEL_little',
'REPORTED_USAGE_LEVEL_very_high', 'REPORTED_USAGE_LEVEL_very_little',
'CONSIDERING_CHANGE_OF_PLAN_considering',
'CONSIDERING_CHANGE_OF_PLAN_never_thought',
'CONSIDERING_CHANGE_OF_PLAN_no', 'CONSIDERING_CHANGE_OF_PLAN_perhaps'],
dtype='object')
[0.02188422 0.1870612 0.15790887 0.0906787 0.20374381 0.11305089
0.05295354 0.04541263 0.00493094 0.01041318 0.01160744 0.00896044
0.00668551 0.01612369 0.01104486 0.01482145 0.01519049 0.00761096
0.01313275 0.00678443]변수중요도 그래프 그리기 함수
def plot_feature_importance(importance, names): # 중요도 값과 변수 이름을 numpy배열로 반환 feature_importance = np.array(importance) feature_names = np.array(names) data={'feature_names':feature_names,'feature_importance':feature_importance} fi_df = pd.DataFrame(data) # 중요도 값 기준으로 내림차순 정렬 fi_df.sort_values(by=['feature_importance'], ascending=False,inplace=True) fi_df.reset_index(drop=True, inplace = True) plt.figure(figsize=(10,8)) # x축: 중요도 값 & y축: 변수 이름 sns.barplot(x='feature_importance', y='feature_names', data = fi_df) plt.xlabel('FEATURE IMPORTANCE') plt.ylabel('FEATURE NAMES') plt.grid()# 위에서 만든 함수를 실행해서 시각화 수행 plot_feature_importance(model.feature_importances_, list(x_train))
max_depth에 따른 모델 성능 평가
depths = [1, 2, 3, 4, 5]
train_acc = []
val_acc = []
for depth in depths:
print("\n \n \n")
print(f"================ max_depth = {depth} =================")
# 모델 생성 및 학습
model = DecisionTreeClassifier(max_depth=depth, random_state=20)
model.fit(x_train, y_train)
# 예측
y_train_pred = model.predict(x_train)
y_val_pred = model.predict(x_val)
# 성능 평가
train_accuracy = accuracy_score(y_train, y_train_pred)
val_accuracy = accuracy_score(y_val, y_val_pred)
train_acc.append(train_accuracy)
val_acc.append(val_accuracy)
print(f"훈련 정확도(train acc): {train_accuracy:.4f}")
print(f"검증 정확도(val acc): {val_accuracy:.4f}")
print(classification_report(y_val, y_val_pred, digits=4))
# 트리 시각화
plt.figure(figsize=(18,6))
plot_tree(model, feature_names=x_train.columns, filled=True, fontsize=10)
plt.title(f"Decision Tree (max_depth={depth})", fontsize=14)
plt.show()
# 변수 중요도 시각화
plot_feature_importance(model.feature_importances_, list(x_train))
plt.title(f"Feature Importance (max_depth={depth})", fontsize=14)
plt.show()
================ max_depth = 1 =================
훈련 정확도(train acc): 0.6161
검증 정확도(val acc): 0.6165
precision recall f1-score support
LEAVE 0.5816 0.7773 0.6654 1962
STAY 0.6829 0.4617 0.5509 2038
accuracy 0.6165 4000
macro avg 0.6322 0.6195 0.6081 4000
weighted avg 0.6332 0.6165 0.6071 4000
================ max_depth = 2 =================
훈련 정확도(train acc): 0.6557
검증 정확도(val acc): 0.6495
precision recall f1-score support
LEAVE 0.7062 0.4888 0.5777 1962
STAY 0.6204 0.8042 0.7004 2038
accuracy 0.6495 4000
macro avg 0.6633 0.6465 0.6391 4000
weighted avg 0.6625 0.6495 0.6402 4000
================ max_depth = 3 =================
훈련 정확도(train acc): 0.6921
검증 정확도(val acc): 0.6895
precision recall f1-score support
LEAVE 0.7242 0.5928 0.6519 1962
STAY 0.6662 0.7826 0.7198 2038
accuracy 0.6895 4000
macro avg 0.6952 0.6877 0.6858 4000
weighted avg 0.6947 0.6895 0.6865 4000
================ max_depth = 4 =================
훈련 정확도(train acc): 0.7024
검증 정확도(val acc): 0.7080
precision recall f1-score support
LEAVE 0.6760 0.7773 0.7231 1962
STAY 0.7494 0.6413 0.6912 2038
accuracy 0.7080 4000
macro avg 0.7127 0.7093 0.7071 4000
weighted avg 0.7134 0.7080 0.7068 4000
================ max_depth = 5 =================
훈련 정확도(train acc): 0.7053
검증 정확도(val acc): 0.7025
precision recall f1-score support
LEAVE 0.6926 0.7074 0.6999 1962
STAY 0.7124 0.6977 0.7050 2038
accuracy 0.7025 4000
macro avg 0.7025 0.7026 0.7025 4000
weighted avg 0.7027 0.7025 0.7025 4000
max_depth가 높아질수록 훈련 정확도는 높아짐!
But, 검증 정확도는 일정 깊이 이후 오히려 떨어짐 -> overfitting 발생했기 때문
- Overfitting(과적함)이란?
훈련 데이터에만 너무 잘 맞춰져서 새로운 데이터(val/test data)에서는 성능이 떨어지는 현상
🌱Decision Tree 이해하기
1) 분할(spilt)
집단 분할하기
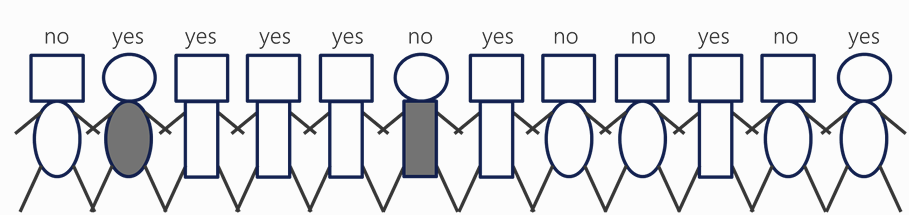
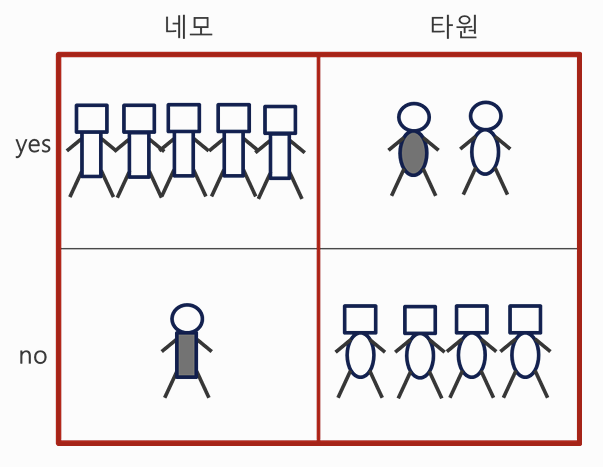
- 의사결정 나무는 특정 기준(feature)을 기준으로 데이터를 여러 집다능로 나눔
- 만약 몸통모양을 기준으로 분류했을 때,
- 네모 집단 -> yes
- 타원 집단 -> no
로 구분할 수 있다면, 해당 기준은 데이터를 잘 나눈 것임!!
- 즉, "얼마나 잘 나누었는가"를 수치화 해서 측정
순도와 불순도
- 순도(Purity): 한 집단에 동일한 클래스가 얼마나 모여 있는지를 나타냄.
-> 한 클래스만 있으면 순도 100% - *불순도(Impurity): * 서로 다른 클래스가 섞여 있을수록 높아짐
-> 불순도 = 1 - 순도
지니 불순도(Gini Impurity)
- 분류 후 얼마나 잘 분류했는지 평가하는 지표
- 얼마나 순도가 증가했는지, 불순도가 감소했는지를 나타냄
- 불순도가 줄어들수록 모델이 데이터를 잘 나눈 것을 의미
-> 즉, 불순도 감소 = 분류 성능 향상
-> 반대로 불순도 감소가 적으면, 잘못 분류했을 가능성 ↑
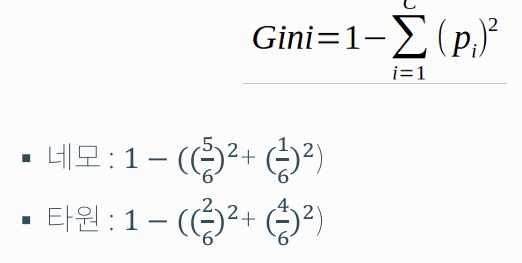
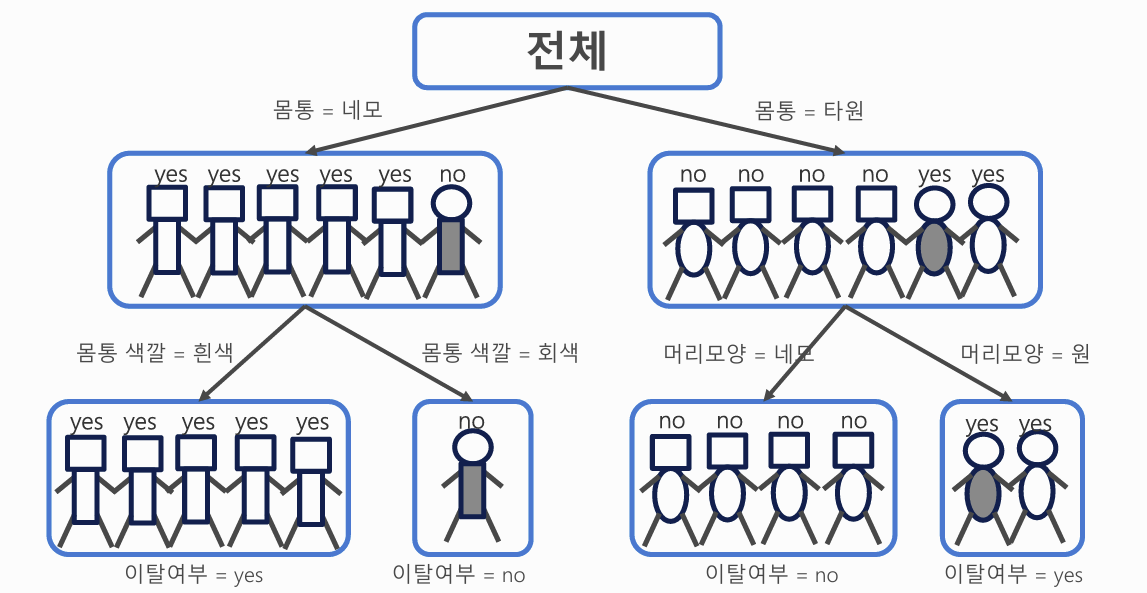
2) 트리 만들기
정보 증가량(Infomation Gain)
- 트리를 분할할 때, 각 분할 기준이 얼마나 불순도를 줄였는지를 평가
- 엔트로피나 지니 계수 같은 지표를 활용해 계산
즉, Information Gain은
“이 분할(feature)이 데이터를 얼마나 깔끔하게 나눴는가”를 수치로 표현한 것!
💡정리 요약
| 개념 | 의미 | 좋을수록 |
|---|---|---|
| 순도 (Purity) | 한 집단이 한 클래스만으로 구성됨 | 높을수록 좋음 |
| 불순도 (Impurity) | 여러 클래스가 섞여 있음 | 낮을수록 좋음 |
| 지니 불순도 (Gini Impurity) | 분류의 혼잡도를 수치화 | 낮을수록 좋음 |
| 정보 증가량 (Information Gain) | 분류 후 불순도가 얼마나 감소했는가 | 높을수록 좋음 |
🌱블로그 챌린지
[지금까지의 학회 활동에 대한 소감]
일단 너무 만족하면서 수업을 듣고 있다. 훌륭한 강사님, 체계적인 교육 시스템, 다양한 원데이 클래스, 학회생들을 위한 혜택 등등 학회원으로서 얻어 갈 수 있는 점이 많다고 생각했다. 이번 기수 활동이 끝나도 다음 기수에 또 이어서 새로운 수업을 듣고 싶다는 마음도 들었다! 그정도로 아주 만족 중이다 ㅎㅎ
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 9주차 (0) | 2026.01.04 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 8주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 5주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 4주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 3주차 (0) | 2026.01.04 |