🏹로지스틱 회귀
Logistic Regression
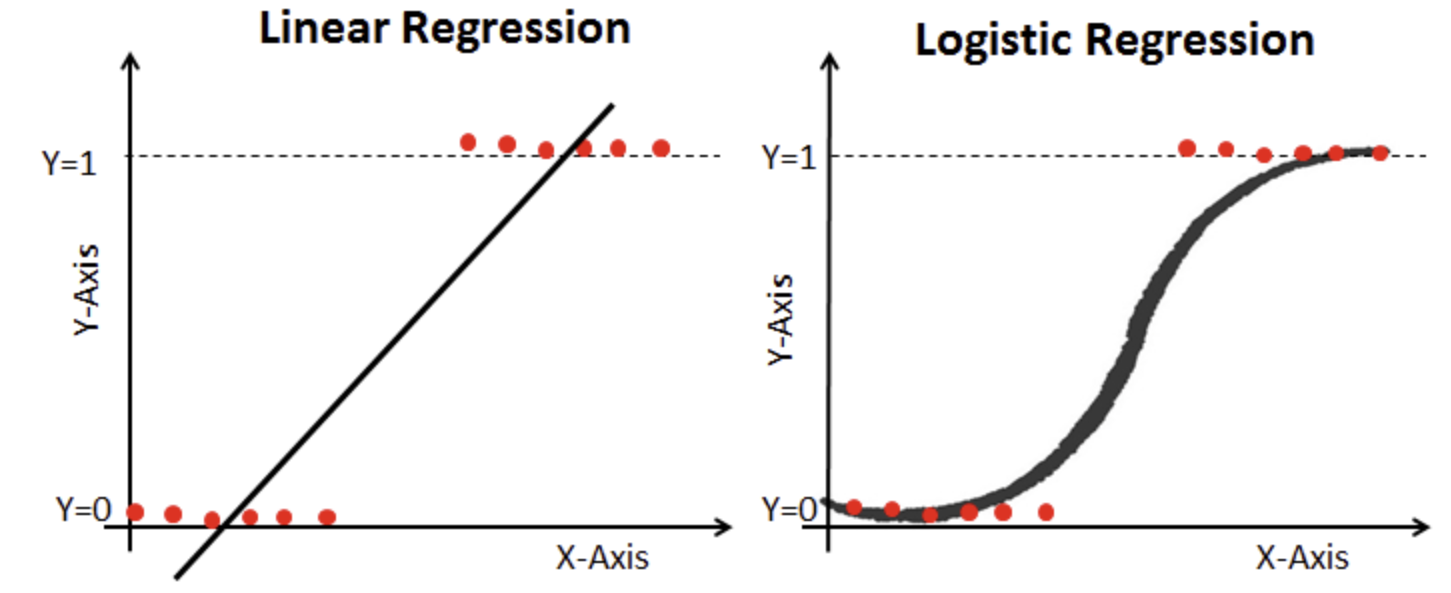
문제점
- 만약, 회귀식이 f(x) = 0.7*x - 0.2 라면 -> f(x)의 범위는 (-∞, ∞)
- 그러나 실제 Y의 값은 0부터 1임!
해결법
- x가 커질수록 f(x)는 ∞가 아닌 1에 가까워짐
- x가 작아질수록 f(x)는 0에 가까워짐
로지스틱 회귀
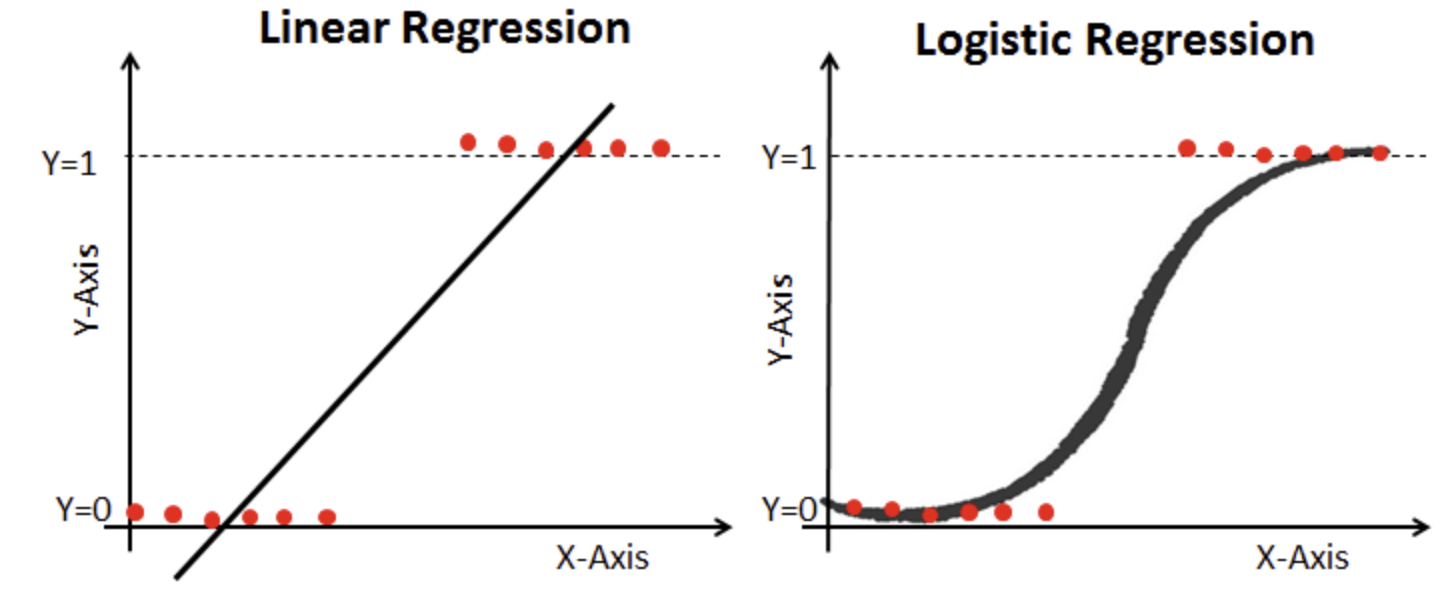
- 개념:
- 선형회귀의 결과를 확률(0~1)로 변환하기 위해 사용하는 분류 기법
- 선형 회귀 결과를 시그모이드 함수(Sigmoid function)를 통하여 확률값으로 변환
- 함수식:
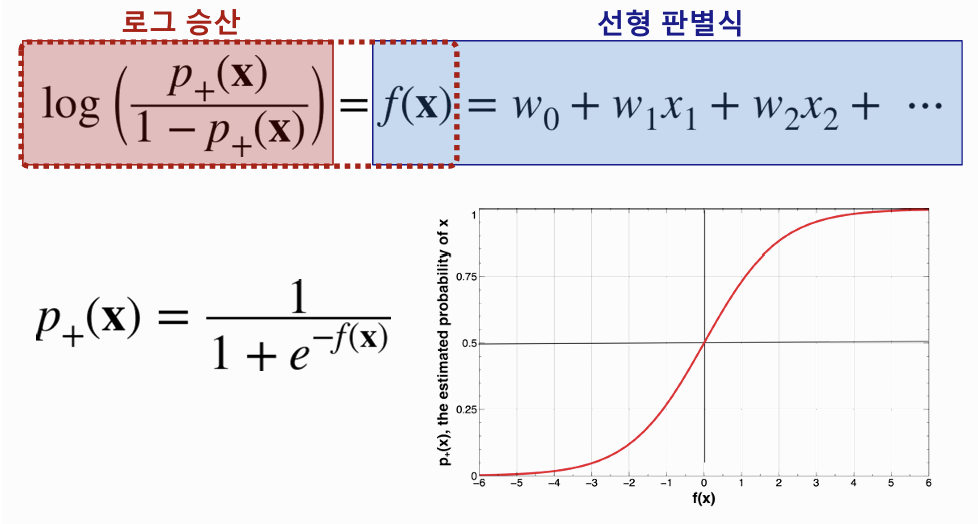
로지스틱 회귀 해석하기

- 파라미터(계수=coefficient)가 음수이면 확률(P(x))은 내려간다.
- 파라미터가 양수이면 확률은 올라간다. (= 1일 확률이 높다)
분류문제 평가:
Confusion Matrix

| 예측 Positive | 예측 Negative | |
|---|---|---|
| 실제 Positive | TP | FN |
| 실제 Negative | FP | TN |
- Confusion Matrix: 실제값(Actual)과 예측값(Predicted)에 대한 교차표
- TP (True Positive): 실제로 Positive인데 맞게 Positive로 예측
- TN (True Negative): 실제로 Negative인데 맞게 Negative로 예측
- FP (False Positive, Type I Error): 실제는 Negative인데 Positive로 잘못 예측
- FN (False Negative, Type II Error): 실제는 Positive인데 Negative로 잘못 예측
Classification report
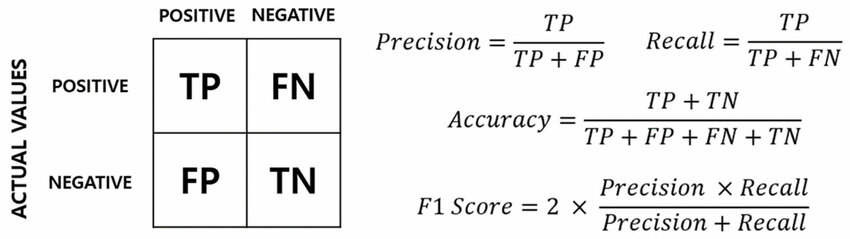
- Recall (재현율, 민감도, Sensitivity): 실제 Positive 중에서 모델이 맞게 Positive로 예측한 비율
- Precision (정밀도): 예측을 Positive라고 한 것 중에서 실제로 Positive인 비율
- F1-Score:
- Precision과 Recall의 조화 평균
- 둘 중에 하나라도 낮으면 F1-Score 낮아짐
- 분자가 같지만 분모가 다를 경우 조화평균 사용
- Accuracy (정확도): 전체 중 맞춘 비율
- macro avg (산술평균): 각 클래스별 지표를 단순 평균 (클래스 크기 고려 X).
- weighted avg (가중평균): 각 클래스별 지표를 데이터 개수(가중치)에 맞는 평균
🏹모델링 실습
1. 환경 준비
(1) import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split(2) 데이터 준비
# admit: 합격 결과 -> target
# gre: 대학원 시험 결과 
2. 데이터 전처리
(1) x, y 분할
target = 'admit'
x = data.drop(target, axis=1)
y = data.loc[:, target](2) 가변수화
cat_cols = ['rank']
x = pd.get_dummies(x, columns = cat_cols, drop_first = True) # 다중 공선성 방지(3) 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random_state = 20)3. 모델링
(1) 모델 선택
model = LogisticRegression()(2) 모델링(학습)
model.fit(x_train, y_train)
# 모델의 coeficient, intercept 확인
model.coef_
list(x_train)
model.intercept_-- 결과 --
array([[ 0.00358039, 0.64445615, -0.0287298 , -1.05014577, -0.91151163]])
['gre', 'gpa', 'rank_2', 'rank_3', 'rank_4']
array([-4.60598403])(3) 검증: 예측
pred = model.predict(x_val)
pred-- 결과 -- (결과는 0.5 기준으로 cut off)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0,
1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 1, 0])[예측 결과를 확률로 뽑고 싶다면]
pred_p = model.predict_proba(x_val)
pred_p[:10]array([[0.51883085, 0.48116915], -> 이거 두 값을 합치면 1이 나옴
[0.6080832 , 0.3919168 ],
[0.54826207, 0.45173793],
[0.78828055, 0.21171945],
[0.85975612, 0.14024388],
[0.583778 , 0.416222 ],
[0.56046632, 0.43953368],
[0.5272615 , 0.4727385 ],
[0.70368505, 0.29631495],
[0.66466552, 0.33533448]])(4) 검증: 평가
accuracy_score( y_val, pred)
# 결과: 0.69166666666666674. 분류 모델 평가
(1) Confusion Matrix
confusion_matrix( y_val , pred )-- 결과 --
array([[73, 11],
[26, 10]])ACC = (73+10) / total = 0.6916666666666667
(위에서 얻은 accuracy_score와 같다는 것을 알 수 있음)
(2) classification_report
print(classification_report(y_val , pred))
# classification 메소드는 print문으로 결과를 출력해야 제대로 보임 -- 결과 --
precision recall f1-score support
0 0.74 0.87 0.80 84
1 0.48 0.28 0.35 36
accuracy 0.69 120
macro avg 0.61 0.57 0.57 120
weighted avg 0.66 0.69 0.66 120(3) Confusion Matrix 시각화
# confusion matric 시각화
cm = confusion_matrix( y_val , pred )
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels = ['died', 'survived'])
disp.plot(cmap=plt.cm.Blues)
plt.xticks(rotation=90)
plt.show()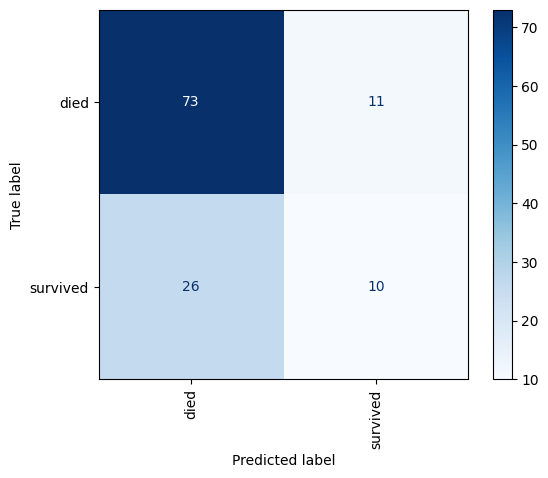
🏹블로그 챌린지
 |
 |
|---|
정규반 수강이 없어도, BDA의 다양한 콘텐츠와 활동에 참여할 수 있는 ✨유연한 멤버십✨💡 이런 분들께 추천드려요!
- 스터디, 조별활동만 참여하고 싶으신 분
- 방학 기간 부트캠프 참여를 원하시는 분
- 정규반 수업보다 콘텐츠 위주로 듣고 싶은 분
- 현직자 강연/커리어 인사이트가 궁금하신 분
🙌 일반 학회원이 되면 누릴 수 있는 혜택 ✔️ 원데이 클래스 ✔️ 현직자 강연 (BDA JOB, BDA WAVE, BDA 페스티벌 등) ✔️ 스터디 & 공모전 ✔️ 커피챗 (실무자와의 커리어 대화) ✔️ 부트캠프 등
📌 지금 QR코드로 간편 지원 가능!
👉 우수 일반학회원에게는 특별 혜택도 준비되어 있어요 🎁
https://www.instagram.com/p/DO51_7PEtN2/?igsh=NDM5ODczOTRmYzFx
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 5주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 3주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 2주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 1주차 (0) | 2026.01.04 |