지도학습 기본 알고리즘1 - 선형회귀
데이터 준비
1. 데이터 전처리
- 모든 셀에는 값이 있어야 한다. -> 그냥 빈 값이라고 해도 NA, NaN과 같은 결측값을 넣어줘야 한다.
- 모든 값은 숫자여야 한다. -> e.g. Yes나 No 같은 값은 1이나 0 같은 값으로 넣는다.
- 값의 범위를 일치시켜야 한다.
2. 가변수화
- 데이터는 머신러닝 알고리즘에 사용하려면 숫자로 변환해야 한다.
- One-Hot-Encoding
- pandas의 get_dummies()와 같은 함수를 사용하여 가변수화 시킨다.

3. 데이터 분할(1) - x, y
- x(input): features, 요인, 설명 변수
- y(output): target, label, 종속 변수
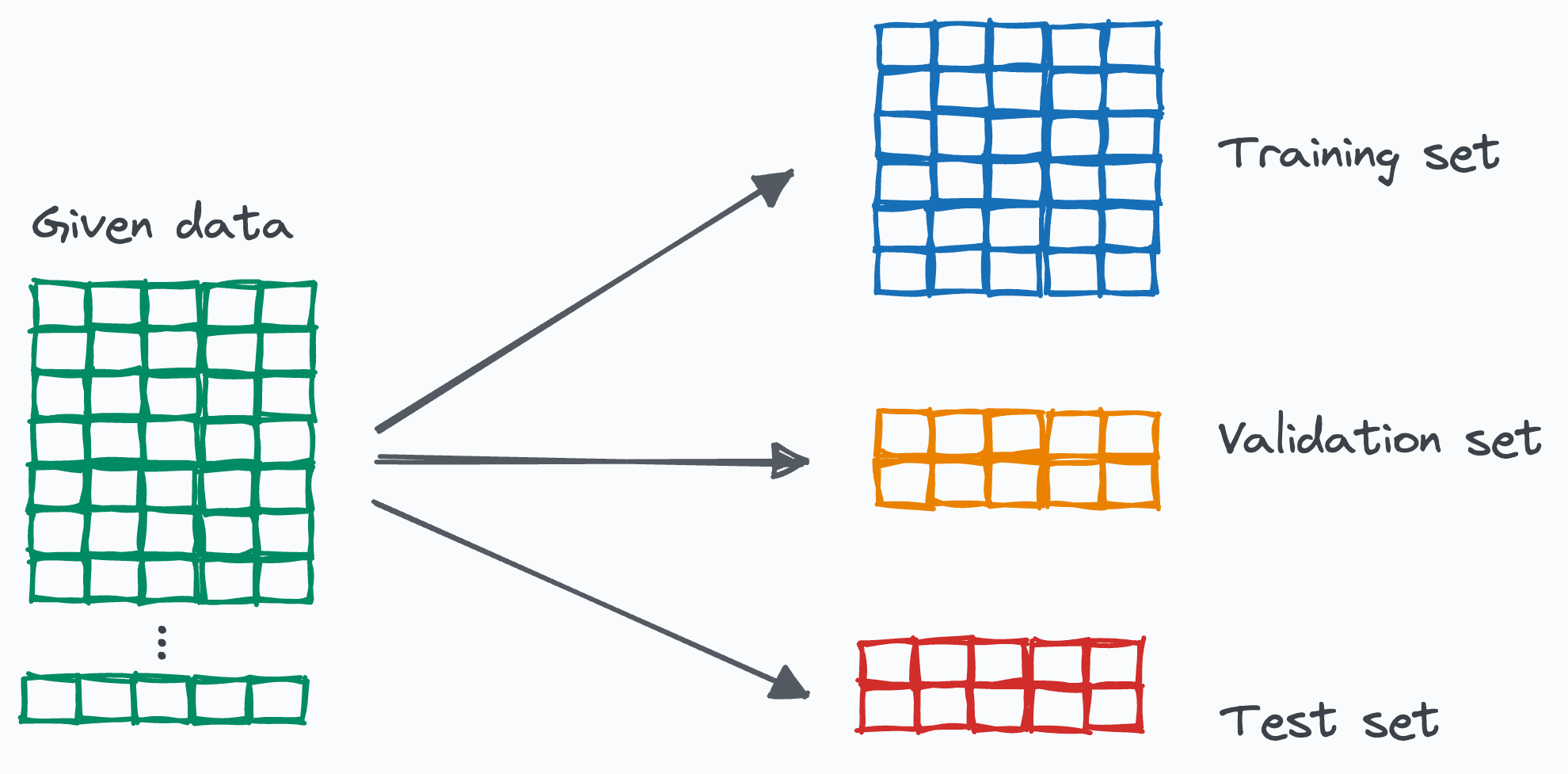
4. 데이터 분할(2) - trian, validation, test
- Train: 학습용, 모델을 생성할 때 사용한다. ex) 문제집 교과서, 교재
- Validation: 검증용, 모델의 성능을 검증하는데 사용한다. ex) 연습문제, 모의고사
- Test: 평가용, 모델의 성능을 평가하기 위한 용도 ex) 찐 수능
- 게임에서 베타 데스트(최종 테스트) 때만 사용하는 데이터를 test data라고 생각하면 된다.
train,validation,test의 비율은 보통 6:2:2 또는 8:1:1로 나누기도 한다.
지도학습 기본 알고리즘1 - 선형회귀
단순회귀 vs 다중회귀
- 단순회귀(Simple Regression): 하나의 feature로 하나의 target을 예측
e.g. 온도라는 하나의 요인만으로 아이스크림 판매량 예측하기 - 다중회귀(Multiple Regression): 복수의 feature로 하나의 target을 예측
e.g. 온도, 습도, 요일 등등 여러 변수를 가지고 아이스크림 판매량을 예측하기
Linear Regression
- 데이터를 하나의 직선으로 요약
- 자료를 설명하는 직선은 여러 개가 될 수도 있다. 그 중에서 전체 오차가 가장 적은 직선을 선택한다.
[직선 선택 방법]
해석적(계산적) 방법: 최소 제곱 법(Least Square)
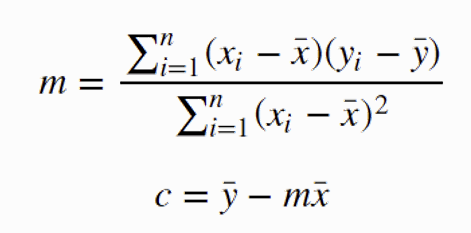
최적화 방법: 오차를 조금씩 줄여가면서 반복적으로 직선을 찾음(경사 하강법)
산점도와 회귀직선
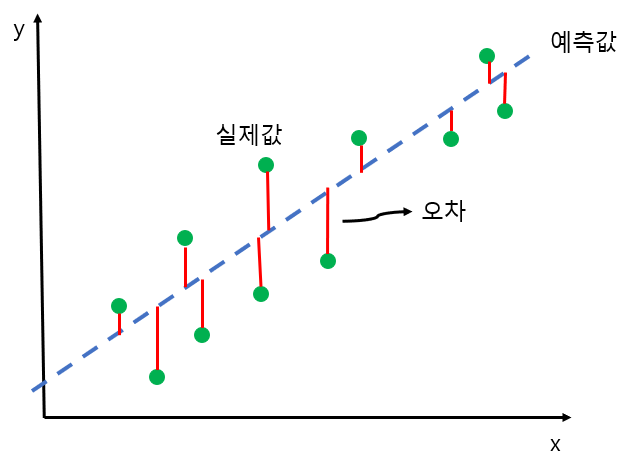
- 산점도(Scatter Plot):
- 데이터를 좌표평면 위 점으로 나타낸 그래프
- x축은 feature, y축은 target
- 회귀 직선: 직선은 y = a*x+ b 라는 직선의 방정식을 갖는다.
모델링 절차
1. 필요한 함수 불러오기
# 데이터 다루는 라이브러리
import numpy as np
import pandas as pd
# 데이터 시각화 라이브러리
import matplotlib.pyplot as plt
# 머신러닝 라이브러리
from sklearn.model_selection import train_test_split # 데이터 분할
from sklearn.metrics import * # 모델 평가 함수들 전체(*)2. 모델 선언
- 모델에 필요한 하이터 파라미터도 설정
model = LinearRegression()3. 학습
.fit이라는 함수 사용- feature들과 target과의 관계, 패턴을 선형회귀 알고리즘을 이용하여 모델로 만든다.
model.fit(x_train1, y_train)4. 모델 내부 열어보기
모델.coef_: 회귀계수 (python에서 마지막에 언더바가 있으면 어떠한 값이다)모델.intercept_: y 절편- e.g. 직선식: y = 4.108*x - 19.756
이것들을 가중치(weight), 파라미터 등이라고 부른다!
print('회귀계수 : ', model1.coef_)
print('절편 : ', model1.intercept_)5. 예측 및 검증 평가
- 학습시킨 모델이 얼마나 정확한지 검증하기 위해 학습할 때 사용하지 않은 데이터셋을 시험
pred1 = model1.predict(x_val1)
6. 평가
- 회귀 모델은 평균오차의 양과 율로 평가한다.
# 평균오차
mean_absolute_error(y_val, pred1)
# R1 score로 평가
r2_score(y_val, pred1)
# MSE -> 평균제곱 오차
mean_squared_error( y_val , pred1 )
# RMSE -> 제곱근 평균제곱오차
root_mean_squared_error( y_val , pred1)
# MAE -> 평균절대오차
mean_absolute_error(y_val , pred1)
# MAPE -> 평균절대백분율오차
mean_absolute_percentage_error(y_val , pred1)
R² Score
R² Score (결정계수, Coefficient of Determination)란?
정의: 모델이 실제 데이터를 얼마나 잘 설명하는지를 나타내는 지표
범위: 일반적으로 0 ~ 1 사이 값 (가끔 음수가 될 수도 있음)
해석
R² = 1 → 모델이 데이터를 완벽하게 설명함 (예측값 = 실제값)
R² = 0 → 모델이 데이터를 전혀 설명하지 못함 (단순히 평균으로 예측한 것과 같음)
R² < 0 → 모델이 오히려 평균으로 예측하는 것보다 못한 경우
2주차 블로그 챌린지🔥

BDA학회 인스타입니다! 빅데이터 분석 학회로 데이터와 관련된 다양한 정보성 카드뉴스나 취업 정보, 부트캠프 등 다양한 정보를 확인하실 수 있습니다. 데이터에 관심이 있으시다면 팔로우 하시는 것을 추천드립니다🤗
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 5주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 4주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 3주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 1주차 (0) | 2026.01.04 |