🌳기본 알고리즘3: Decision Tree
Decision Tree(의사결정 나무)
특정 변수에 대한 규칙을 적용하여, 나무의 가지가 뻗는 형태로 분류해 나가는 알고리즘
[장점]
- 분석 과정이 직관적이고 이해하기 쉬움
- Regression, Classification 둘 다 가능
- 계산 비용이 낮아 대규모의 데이터 셋에서도 비교적 빠르게 연산 가능
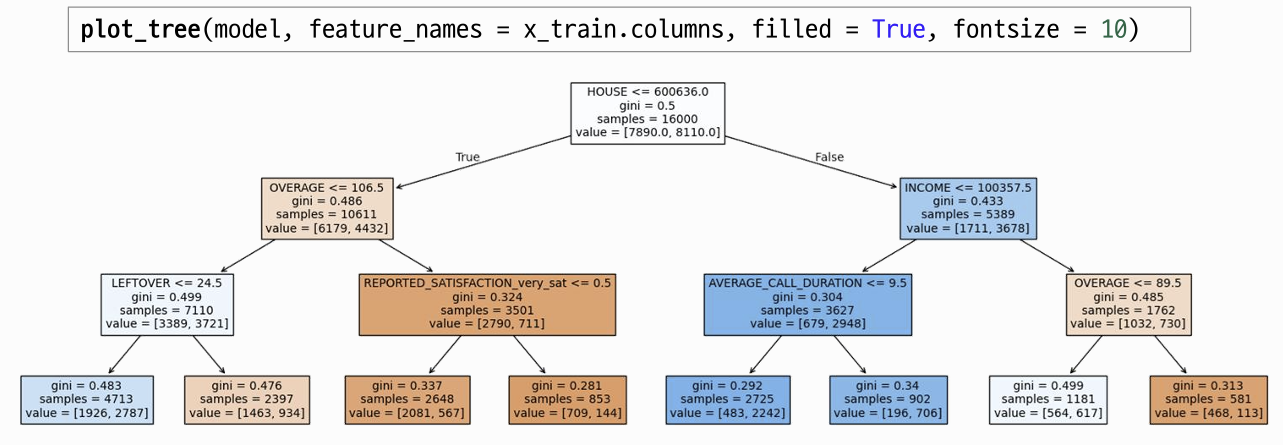
모델링 기본 틀
- 필요한 함수 불러오기
# 모델링을 위해
from sklearn.tree import DecisionTreeClassifier
# 평가를 위해.
from sklearn.metrics import *- 선언 및 학습
# 모델 선언
model = DecisionTreeClassifier()
# 학습
model.fit(x_train, y_train)- 검증: 예측
pred = model.predict(x_val)- 검증: 평가
confusion_matrix(y_val, pred)
print(classification_report(y_val, pred, digits = 4))[추가개념]
decision tree에서 분류 말고 회귀를 쓰고 싶으면 다음과 같은 모델을 선언하면 됨.
| 목적 | 모델 이름 | import 경로 |
|---|---|---|
| 분류(Classification) | DecisionTreeClassifier |
from sklearn.tree import DecisionTreeClassifier |
| 회귀(Regression) | DecisionTreeRegressor |
from sklearn.tree import DecisionTreeRegressor |
🌳모델링 실습
[해결 문제]
어느 통신회사의 데이터분석가라고 할 때, 회사는 약정기간이 끝난 고객이 번호이동(이탈)해 가는 문제를 해결한다.
1. 환경준비
1) import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split2) 데이터 준비
path = 'https://@@@@@@.csv'
data = pd.read_csv(path)
data.head()2. 데이터 전처리
1) 변수 정리
-> id나 주민번호, 전화번호, 사번과 같은 불필요한 변수는 drop
drop_cols = ['id']
data.drop(drop_cols, axis = 1, inplace = True)2) x, y 분할
target = 'CHURN;
x = data.drop(target, axis = 1)
y = data.loc[:, target]3) 가변수화
dumm_cols = ['REPORTED_SATISFACTION','REPORTED_USAGE_LEVEL','CONSIDERING_CHANGE_OF_PLAN']
x = pd.get_dummies(x, colums = dumm_cols, drop_first = True)4) train, val 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 20)3. 모델링
1) 필요한 함수 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import *2) 모델 선언
model = DecisionTreeClassifier()3) 모델링(학습)
model.fit(x_train, y_train)4) 검증: 예측
pred = model.predict(x_val)5) 검증: 평가
- confusion matrix
confusion_matrix(y_val, pred)array([[1143, 819],
[ 739, 1299]])- classification report
print(classification_report(y_val, pred, digits = 4)) # 소숫점 4자리까지만 보이기
precision recall f1-score support
LEAVE 0.6073 0.5826 0.5947 1962
STAY 0.6133 0.6374 0.6251 2038
accuracy 0.6105 4000
macro avg 0.6103 0.6100 0.6099 4000
weighted avg 0.6104 0.6105 0.6102 4000Precision(정밀도): 모델이 정답이라고 예측한 것 중 실제로 맞은 비율
Recall(재현율): 실제 정답 중에서 모델이 잘 찾아낸 비율
F1-score: precision과 recall의 조화 평균
Accuracy(정확도): 전체 중에서 맞춘 비율
🌳 블로그 챌린지
빅데이터 분석 학회 BDA는 학생들의 중간, 기말고사 일정에 맞춰 휴회 기간을 가진다. 이 기간 동안 학회원들이 시험에 집중할 수 있도록 배려하며, 휴회 기간이 끝난 후 다시 BDA에 집중하게 된다. 대학생들이 많이 참여하는 학회인 만큼 너무 좋은 제도라고 생각했다.
휴회기간이 끝났기 때문에 이번 강의에서 강사님이 그동안의 내용을 함께 복기해 주셔서 학습의 흐름을 되찾을 수 있었다. 5주차 수업을 시작으로 남은 수업까지 성실하게 참여하고 무사히 수료할 수 있도록 노력해야 겠다!
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 8주차 (0) | 2026.01.04 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 4주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 3주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 2주차 (0) | 2026.01.04 |