
📈 성능 - 교차검증
성능의 목표와 향상
1. 모델링의 목표
- 모집단(population) : 우리가 알고 싶은 모든 데이터의 집합. 과거의 데이터, 미래의 데이터도 모집단의 부분집합에 포함.
- 우리가 가지고 있는 모든 데이터셋은 모집단의 부분집합임 = Training Set 역시 모집단의 부분집합.
- 따라서 모델링의 목표는 부분집합을 학습해서 모집단(혹은 모집답의 다른 부분집합)을 적절히 예측하는. 즉 적절한 성능(일반화 성능)을 확보하는 것.
2. 성능 향상을 위한 노력
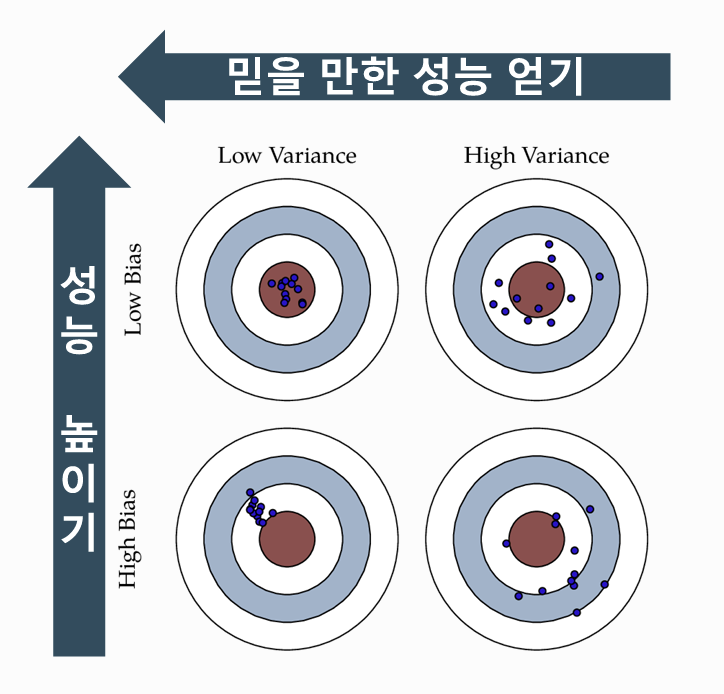
[일반화 성능]
- 모델이 처음 보는 새로운 데이터에서도 얼마나 잘 예측하는지 나타내는 객관적인 성능 지표.
- 단순히 훈련 데이터에서 높은 점수를 내는 것(=과적합)과는 구별해야 함!
[성능을 높이는 방법]
*방법 1. 성능의 평균으로 평가 *
- 하나의 훈련/검증 데이터 분할에 의존하지 않고, 여러 번 성능을 측정해 평균을 사용하면 더 안정적인 성능 추정이 가능.
- 분할 방식에 따라 들쑥날쑥
방법 2. 학습 데이터(train data) 늘리기
- Variance(분산) 감소 → 모델의 불안정성 감소
- Bias(편향) 감소 → 모델이 더 복잡한 관계를 학습 가능
방법 3. 튜닝하기
- 적잘한 하이퍼파라미터 설정
- Bias 감소
- 과적합 피하기
성능의 평균으로 평가하기
방법 1. 여러번 반복실행, 평균 성능
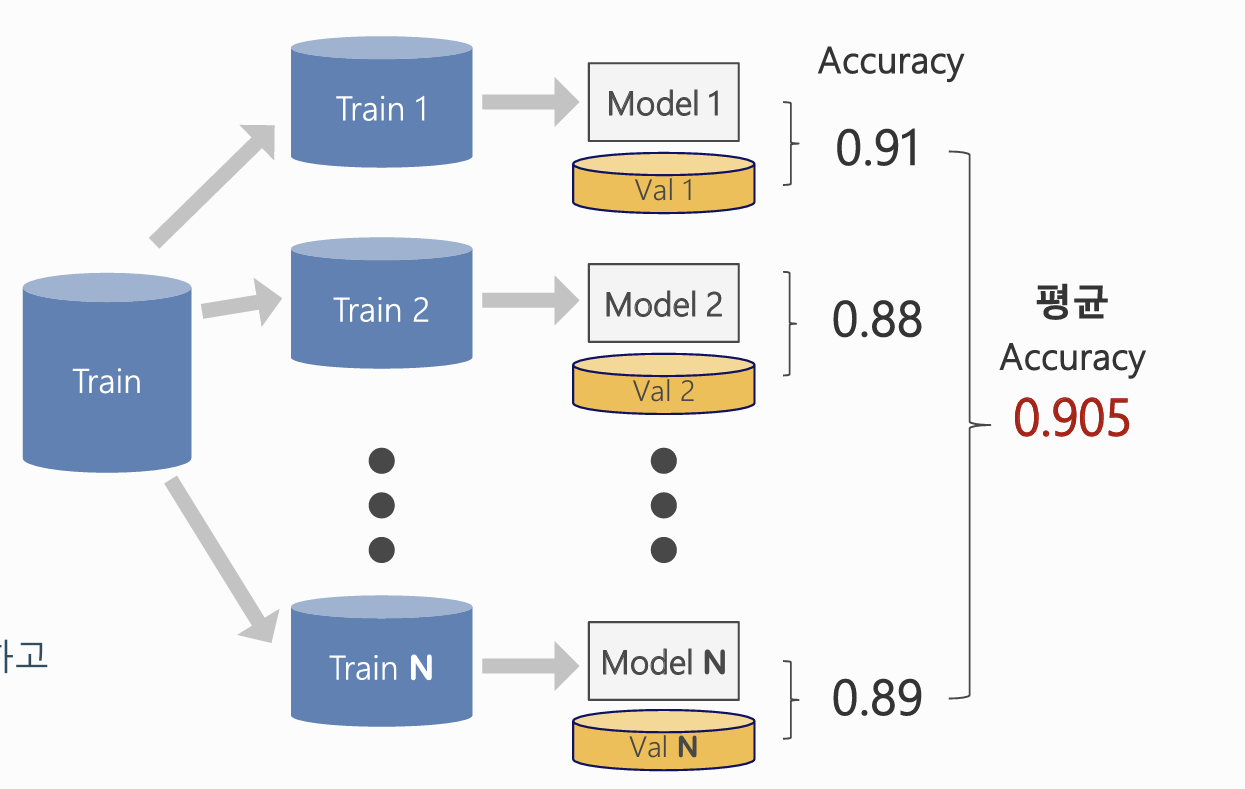
- 다음의 조건들은 동일하게 유지한 채 모델을 여러개 생성
ex) 특정 변수들, 특정 알고리즘, 특정 하이퍼파라미터 값 - 각 모델에 대해 동일한 Train data를 넣고 학습
- 각각의 모델의 validation data의 Accuracy를 수집하여, Accuracy들의 평균값을 최종 성능으로 사용
→ 장점: 간단하고 직관적
→ 단점: Train/Validation 분할에 따라 여전히 편향이 발생할 수 있음
방법 2. k-fold cross validation
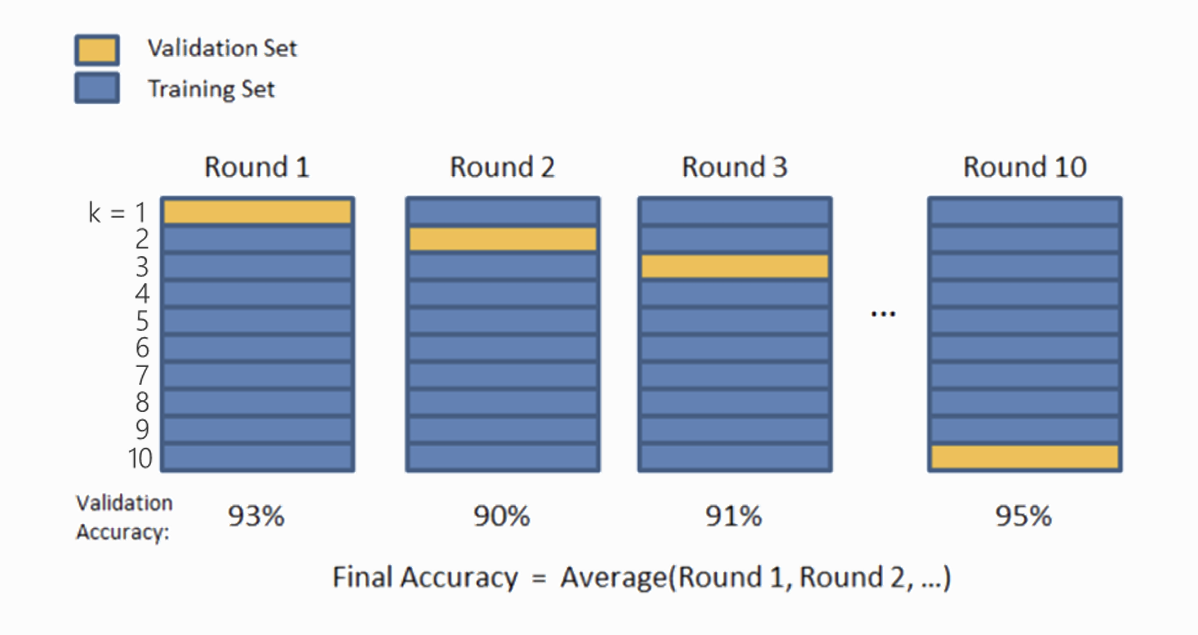
- 전체 데이터를 k개의 동일한 크기 조각으로 나눔.
- 각 조각 데이터가 한 번씩은 Validation Set이 되도록 k번 반복하여 학습 및 평가
- 최종 성능은 k회의 성능 평가의 평균값
→ 장점: 모든 데이터가 한 번씩은 Validation 용도로 사용되므로 데이터 낭비가 없음.
cross_val_score를 이용한 교차검증

사용하는 함수 : cross_val_score
개별 모델의 Cross Validation 성능 측정 : 모델을 선언한 후, 학습을 .fit 대신
cross_val_score(모델, x, y, fold의 개수)튜닝 과정에서의 교차검증 -> 튜닝 시 옵션으로 cv 값 지정
RandomizedSearchCV(model, param_grid, cv=10) GridSearchCV(model, param_grid, cv=10)k값은 보통 5~10 사이에서 많이 사용됨
- 데이터가 충분하면 10
- 부족하면 5
데이터 늘리기
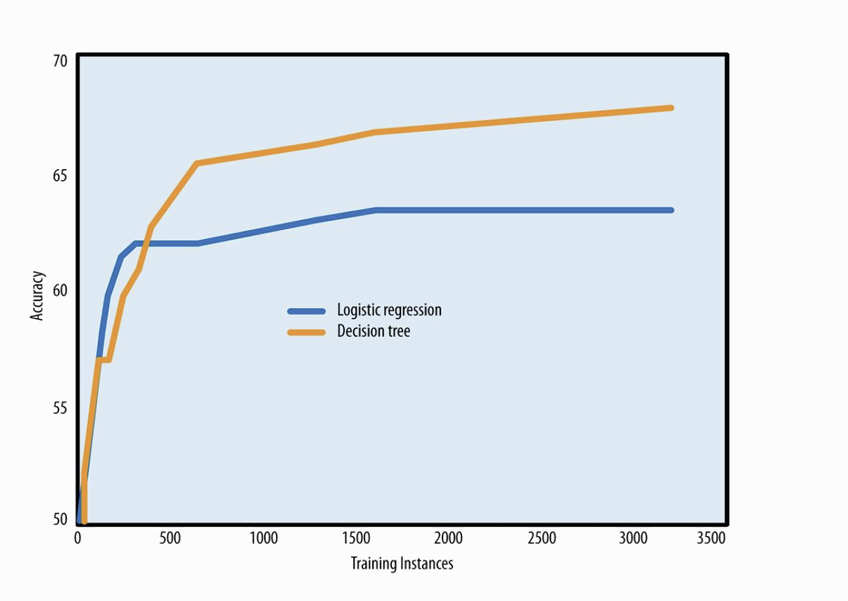
학습용 데이터의 양과 성능
- Training Set의 크기가 커지면 모델 성능이 향상됨.
- Learning Curve : 훈련 데이터의 크기 변화에 따라 Train/Validation 성능이 어떻게 달라지는지 보여주는 그래프
데이터가 많을수록 항상 좋은가?
- 데이터가 많을 수록 성능이 개선되지만, 어느 지점부터 성능 향상도가 꺾임.
- 그후는 데이터 증가에 따라 성능개선 효과는 급격히 줄어듦.
- But, 데이터가 많은 만큼 모델링 속도는 늦어짐.
- 따라서 적절한 데이터 크기를 찾는 방법 -> Elbow Method
Elbow Method
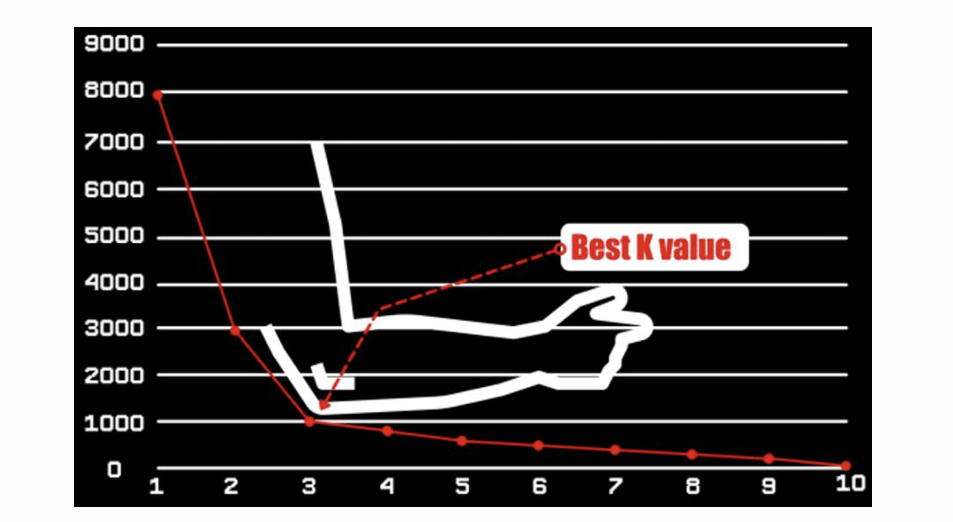
- 성능 향상이 급격히 줄어들기 시작하는 '팔꿈치 지점' 주변을 최적의 데이터 크기로 판단
- Trade-Off 관계일 때, 적절한 지점을 찾기 위한 휴리스틱 방법
- Elbow Method는 완벽한 해답을 보장하는 공식적인 알고리즘은 아니고, 경험 기반으로 합리적인 지점을 선택하는 휴리스틱(heuristic) 접근임.
- 휴리스틱 법(heuristics) : 불충분한 시간이나 정보로 인하여 합리적인 판단을 할 수 없거나, 체계적이면서 합리적인 판단이 굳이 필요하지 않은 상황에서 사람들이 빠르게 사용할 수 있게 보다 용이하게 구성된 간편추론의 방법
📈 모델링 실습
1. Data 전처리
# 필요한 함수 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
# 데이터 읽어오기
path = "https://@@@.CSV"
data = pd.read_csv(path)
data.drop('EmployeeNumber', axis = 1, inplace = True)
data.head()
# 타켓 지정
target = 'Attrition'
x = data.drop(target, axis=1)
y = data.loc[:, target]가변수화
dum_cols = ['Department','Gender','JobSatisfaction','MaritalStatus','OverTime' ]
x = pd.get_dummies(x, columns = dum_cols, drop_first = True)2. Random Sampling
- 데이터를 랜덤 분할하여 모델링 & 예측 수행
- iris는 feature들이 모두 숫자이므로 dummy variable 필요 없음
- Scaling만 필요
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 정분류율을 계산하는 함수
from sklearn.preprocessing import MinMaxScaler # 모든 값을 0~1 범위로 변환하는 함수
from sklearn.tree import DecisionTreeClassifier, plot_tree(1) 반복 실행
# 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2)
# DecisionTree 모델링
model = DecisionTreeClassifier(max_depth = 3)
model.fit(x_train, y_train)
pred = model.predict(x_val)
accuracy_score(y_val, pred) # accuracy는 실행할 때마다 달라짐0.8468085106382979 # 0.7 ~ 0.9 사이에서 실행할 때마다 정분류율이 달라짐 (2) 여러번 반복해서 평균 계산
# progress bar를 볼 수 있는 tqdm 불러오기
from tqdm.auto import tqdm
# decision tree 모델을 100번 반복실행한 정확도 결과를 저장할 리스트
r_dt = []
# 원래 코드: for i in range(50): => 50번 반복
# tqdm(range(100)) : 100번 반복하며 진행 상황을 progress bar로 보여줌
for i in tqdm(range(100)):
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2)
model = DecisionTreeClassifier(max_depth = 3)
model.fit(x_train, y_train)
pred = model.predict(x_val)
r_dt.append(accuracy_score(y_val, pred)) # 예측 결과의 정확도를 계산 후 리스트에 저장 (3) 평균과 표준편차 구하기
r_dt_m, r_dt_s = np.mean(r_dt), np.std(r_dt)
print(f'평균 : {r_dt_m:.4f}, 표준편차 : {r_dt_s:.4f}')평균 : 0.8416, 표준편차 : 0.0215(4) 값의 분포 살펴보기
# 밀도함수 그래프
sns.kdeplot(r_dt)
# 평균값 수직선 그리기
plt.axvline(r_dt_m, color = 'r')
# 표준편차 수직선 그리기
plt.axvline(r_dt_m + r_dt_s, color = 'orange')
plt.axvline(r_dt_m - r_dt_s, color = 'orange')
plt.grid()
plt.show()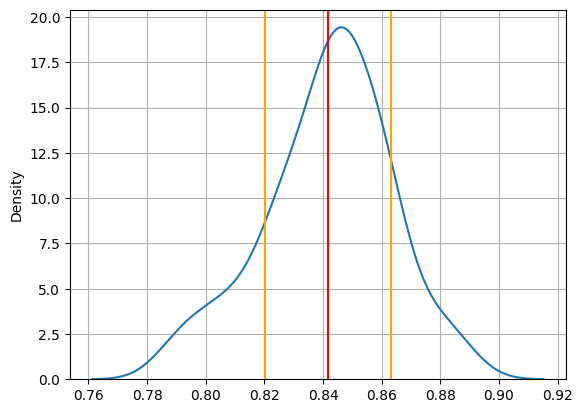
3. KNN 알고리즘으로 실행
k를 지정하지 말고(default)로 50회 수행한 후 결과를 담고 평균으로 일반화 성능 얻어보기
(1) 스케일링
from sklearn.neighbors import KNeighborsClassifier
# 스케일링
scaler = MinMaxScaler()
# train 데이터로 스케일러 학습하고 변환까지
x_train_s = scaler.fit_transform(x_train)
x_val_s = scaler.transform(x_val)(2) 반복해서 성능 측정하기
r_knn = []
scaler = MinMaxScaler() # 스케일러 객체 생성
# 100번 반복하여 KNN 성능 측정
for i in tqdm(range(100)):
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2)
x_train_s = scaler.fit_transform(x_train)
x_val_s = scaler.transform(x_val) # 분할한 걸 스케일링
m = KNeighborsClassifier() # KNN 모델 생성 (기본값: k=5)
m.fit(x_train_s, y_train)
pred = m.predict(x_val_s)
r_knn.append(accuracy_score(y_val, pred))(3) 평균과 표준편차 구하기
r_knn_m, r_knn_s = np.mean(r_knn), np.std(r_knn)
print(f'평균 : {r_knn_m:.4f}, 표준편차 : {r_knn_s:.4f}')평균 : 0.8360, 표준편차 : 0.0205(4) 모델 비교하기
# 밀도함수 그래프
sns.kdeplot(r_dt) # 파란색 그래프
sns.kdeplot(r_knn) # 주황색 그래프
# 평균값으로 수직선 그리기
plt.axvline(r_dt_m, color = 'gray')
plt.axvline(r_knn_m, color = 'gray')
plt.grid()
plt.show()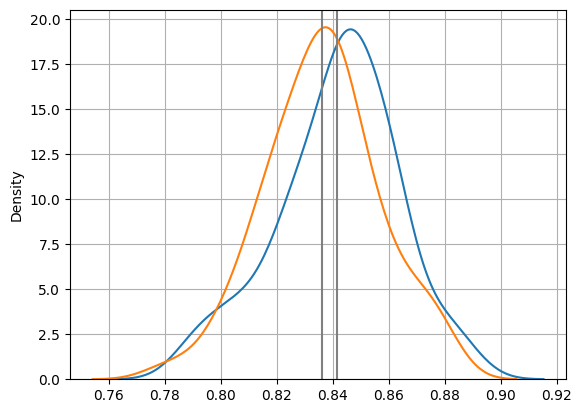
decision tree나 knn 알고리즘의 평균값, 표준편차가 비슷한 것을 알 수 있음.
4. k-fold Cross Validation
(1) 교차검증: DT
# 필요한 패키지, 함수 로딩
from sklearn.model_selection import cross_val_score
# 모델 선언
model = DecisionTreeClassifier(max_depth = 3)# train + validation set을 이용하여 학습, 예측, 평가를 한번에. (여기서는 .fit 이 아님!)
# cv : 데이터를 몇 개로 나누어(k-fold) 교차검증을 수행할지 지정
cv_result = cross_val_score(model, x, y, cv=10)
print(cv_result)
print("평균:", cv_result.mean())
print("표준편차:", cv_result.std()[0.84745763 0.81355932 0.81355932 0.8559322 0.8559322 0.8034188
0.88034188 0.82051282 0.83760684 0.82905983]
평균: 0.8357380848906273
표준편차: 0.02291436687802278(2) 교차검증: knn
scaler = MinMaxScaler()
x_s = scaler.fit_transform(x)
model1 = KNeighborsClassifier()
cv_r2 = cross_val_score(model1, x_s, y, cv = 10)
print(cv_r2)
print("평균:", cv_r2.mean())
print("표준편차:", cv_r2.std())[0.86440678 0.84745763 0.8220339 0.84745763 0.8559322 0.82051282
0.82051282 0.83760684 0.82051282 0.86324786]
평균: 0.8399681297986381
표준편차: 0.017230699117274862(추가) 평균과 표준편차에 따른 그래프 차이
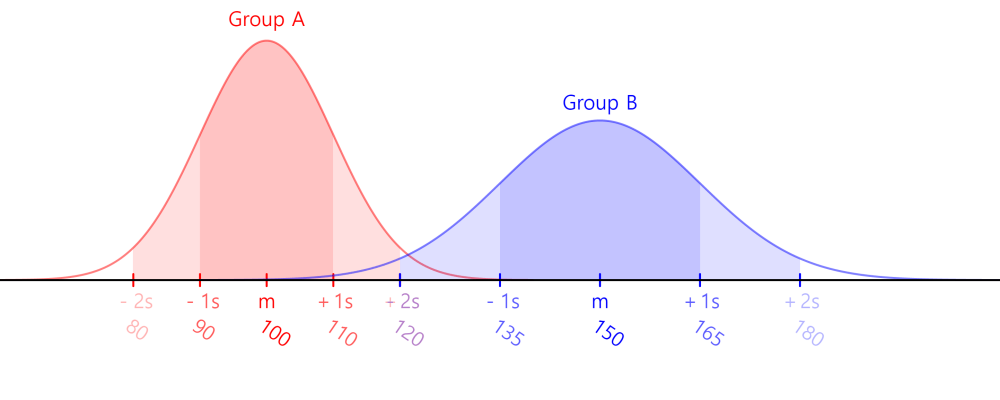
Group A (빨간색)
- 평균(Mean): 낮음
- 표준편차(Standard Deviation): 작음 → 분산이 좁음
- High Bias, Low Variance 상태
Group B (파란색)
- 평균: 높음
- 표준편차: 큼 → 분산이 넓음
- Low Bias, High Variance 상태
평균 올리기 (Bias 낮추기)
- 하이퍼파라미터 튜닝
- 풍부한 feature 사용
Variance 감소 시키기
- 학습 데이터를 늘리기
- 교차검증(k-fold) 사용
- 규제(Regularization) 적용
- KNN이면 K를 조금 키우기
- 트리모델이면 depth를 적당히 조정
📈 8주차 블로그 챌린지
[데이터 분석을 해보고 싶은 주제와 이유]
최근 주식에 관심이 생겨서 그래프를 공부하고 뉴스를 많이 찾아보고 있다. 하지만 주식이 안정적인 제태크 방법은 아니기 때문에 손실을 경험하기도 했다. 이런 경험을 통해 주식 관련 데이터를 분석하고, 미래를 예측할 수 있는 모델을 만들어 보고 싶다고 생각했다.
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 (0) | 2026.01.05 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 9주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 5주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 4주차 (0) | 2026.01.04 |