🧩 성능2 - 최적화(튜닝)
Hyperparameter Tuning이란
- 알고리즘을 이용하여 모델링할 때, 모델 구조나 학습 방식에 영향을 주는 외부 파라미터
- 학습 데이터로부터 자동 학습되지 않고 사전에 사람이 설정
- 하이터 파라미터 튜닝을 통해 성능이 달라질 수 있음
- 튜닝하는 방법에는 정답 X e.g. 지식과 경험 + 다양한 시도 필요
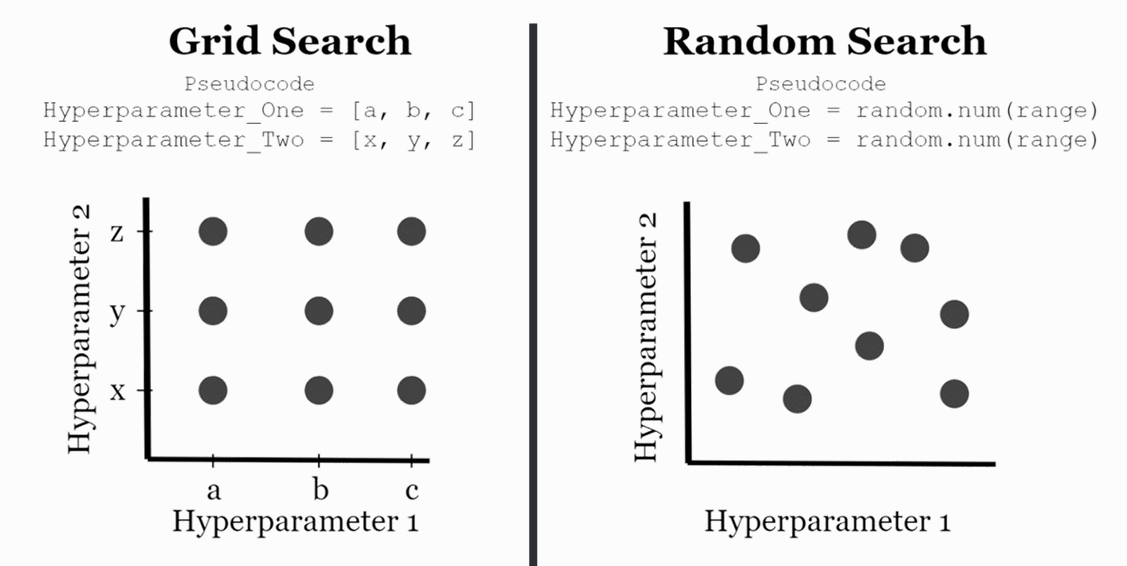
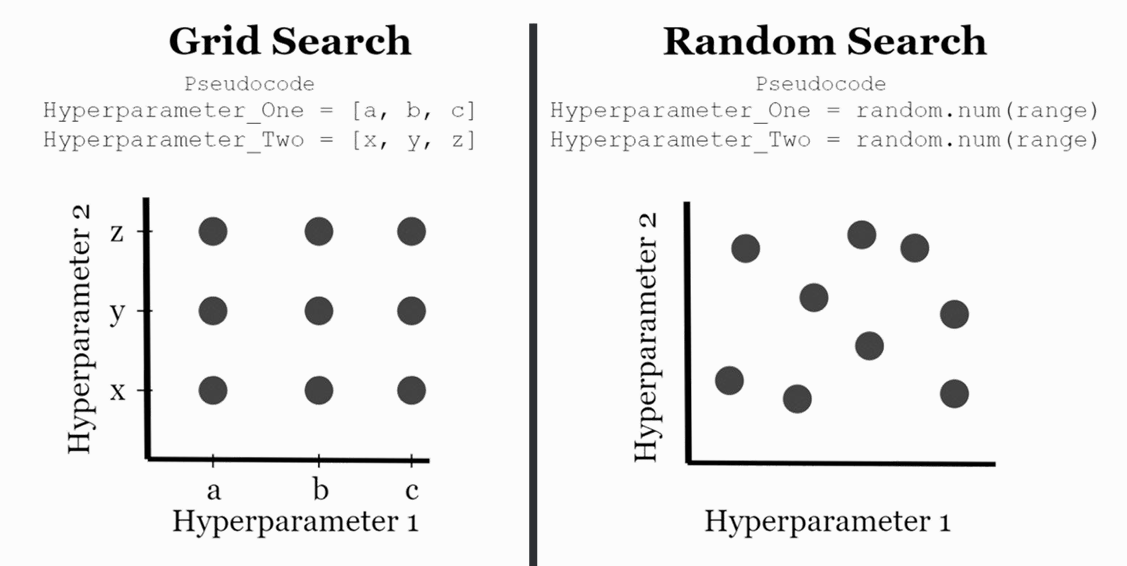
- 대표적인 탐색 e.g. Grid Search, Random Search
※ 모델 파라미터 vs 하이퍼 파라미터
- 파라미터: 학습을 통해 자동으로 결정됨 (ex. 가중치)
- 하이퍼 파라미터: 학습 전에 사람이 설정 (ex. k, depth 등)
Random Search
값의 범위를 지정한 후, 지정한 횟수('n_iter')만큼 무작위로 시도하여 그 중 가장 성능이 좋은 하이퍼 파라미터를 선택하는 방식.
Random Search의 특징
- 장점
- 전체 조합을 탐색하지 않기 때문에 계산 비용이 적음
- 하이퍼 파라미터 공간이 클수록 효율적
- Grid Search 대비 짧은 시간 안에 준수한 성능 확보 가능
- 단점
- 모든 조합을 보지 않기 때문에 최적 조합을 놓칠 수 있음
- 실행할 때마다 결과가 달라질 수 있음 (random_state 미지정 시)
Random Search 실행 방법
1. 범위 지정
- 딕셔너리 형태로 하이퍼 파라미터 범위 지정
- 미지정 하이퍼 파라미터는 기본값(default)으로 지정
# random하게 탐색할 하이퍼 파라미터 범위 지정
rand_param = { 'n_neighbors' : [3,5,7,9,11,13,15,17,19] # 9
, 'metric' : ['euclidean', 'manhattan'] # 2
}
rand_param- 전체 조합 수: 9 X 2 = 18
- Random Search에서는 이 중 일부만 선택하여 실험
2. 함수 불러오기
from sklearn.neighbors import KNeighborsClassifier
# 하이퍼 파라미터 조합을 랜덤하게 선택 / n_iter만큼 반복 수행
# 각 조합마다 Cross Validation 수행
from sklearn.model_selection import RandomizedSearchCV
3. 모델 선언
- 기본 모델 선언
- Random Search 모델 선언
# 기본모델
knn_model = KNeighborsClassifier()
# Random Search 설정.
rand_model = RandomizedSearchCV(knn_model
, rand_param # hyperparameter 범위 지정
, cv=5 # k-fold Cross Validation
, scoring='accuracy'
, n_iter=5 # Random하게 시도할 횟수
)cv=5: 데이터를 5개로 나누어 교차 검증 → 성능의 분산을 줄이고 안정적인 평가 가능
4. 학습
- 기본모델이 아니라 random search 모델로 학습
rand_model.fit(x_train_s, y_train)[내부 동작 과정]
- 하이퍼 파라미터 조합을 랜덤 선택
- 선택된 조합으로 CV 수행
- 평균 성능 계산
- 가장 성능이 좋은 조합 저장
5. 탐색 결과 확인
- 학습 결과는 딕셔너리 형태인 것을 확인할 수 있음 → 그때의 성능 확인이 가능
# 시행에 대한 정보.
rand_model.cv_results_{'mean_fit_time': array([0.08831301, 0.06611972, 0.08200045, 0.02710857, 0.02804184]),
'std_fit_time': array([0.02512902, 0.0144251 , 0.04276259, 0.00086646, 0.00233235]),
'mean_score_time': array([1.21091022, 0.72828774, 0.87529993, 0.4846838 , 0.31746101]),
'std_score_time': array([0.52215558, 0.22987142, 0.38935181, 0.0670369 , 0.05366385]),
'param_n_neighbors': masked_array(data=[15, 3, 17, 17, 11],
mask=[False, False, False, False, False],
fill_value=999999),
'param_metric': masked_array(data=['euclidean', 'euclidean', 'euclidean', 'manhattan',
'euclidean'],
mask=[False, False, False, False, False],
fill_value=np.str_('?'),
dtype=object),
'params': [{'n_neighbors': 15, 'metric': 'euclidean'},
{'n_neighbors': 3, 'metric': 'euclidean'},
{'n_neighbors': 17, 'metric': 'euclidean'},
{'n_neighbors': 17, 'metric': 'manhattan'},
{'n_neighbors': 11, 'metric': 'euclidean'}],
'split0_test_score': array([0.64875 , 0.63958333, 0.65916667, 0.66166667, 0.66041667]),
'split1_test_score': array([0.645 , 0.62125 , 0.63958333, 0.64125 , 0.62916667]),
'split2_test_score': array([0.65458333, 0.6325 , 0.65333333, 0.65125 , 0.64875 ]),
'split3_test_score': array([0.645 , 0.61833333, 0.63541667, 0.65083333, 0.63916667]),
'split4_test_score': array([0.64791667, 0.61625 , 0.64541667, 0.64125 , 0.64166667]),
'mean_test_score': array([0.64825 , 0.62558333, 0.64658333, 0.64925 , 0.64383333]),
'std_test_score': array([0.00350991, 0.00896986, 0.00870584, 0.00759843, 0.01039965]),
'rank_test_score': array([2, 5, 3, 1, 4], dtype=int32)}⭐ 그 중 최적의 파라미터!
# 최적의 파라미터
rand_model.best_params_{'n_neighbors': 17, 'metric': 'manhattan'} # CV 평균 accuracy가 가장 높았던 파라미터 Grid Search
- Random Search와 절차는 동일 (하이퍼 파라미터 범위 지정 → 교차검증 → 성능 비교)
- 차이점:
- 함수가 다름: `GridSearchCV` - 지정된 범위에 대해서 전부 수행하고 최적의 하이퍼 파라미터를 찾아줌.
Grid Search의 특징
- 장점
- 모든 경우를 확인하므로 결과의 신뢰성과 재현성이 높음
- 하이퍼 파라미터와 성능 간의 관계를 명확히 파악 가능
- 단점
- 파라미터 개수나 범위가 커질수록 계산량이 기하급수적으로 증가
- 대규모 탐색 공간에서는 비효율적
Hyperparameter Tuning 시 주의할 점
- 파라미터의 세밀한 조정의로 최적화된 성능을 얻었을지 실제 운영환경에서 성능이 보장되지 않음.
- Validation 데이터에 과도하게 맞춰질 경우 Overfitting 될 가능성 존재.
- 미래에 발생될 데티터는 과거와 다를 수 있음.
즉, 하이퍼 파라미터 튜닝은 일반화 성능을 높이기 위한 수단이지, 성능을 무한히 올리는 방법은 아님!
모델의 복잡도와 과적합
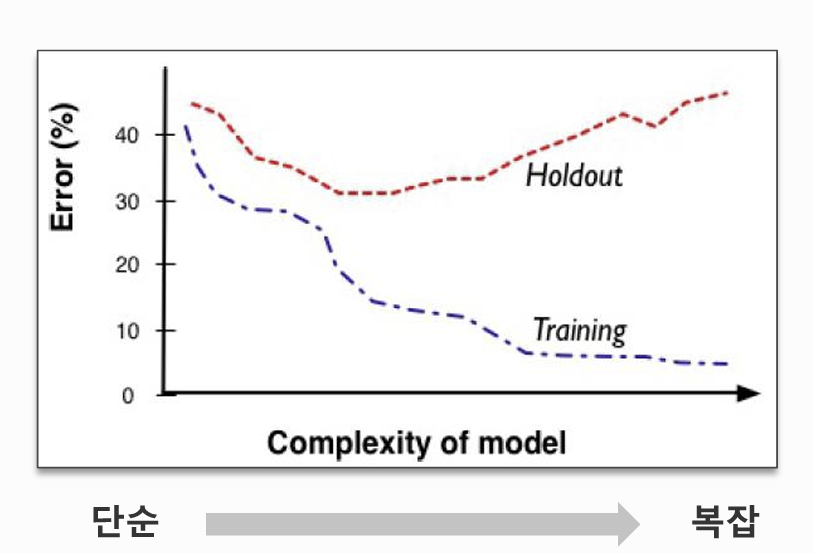
- 적합도 그래프(Fitting Graph)
- x축: 모델의 복잡도 (예: k 값, tree depth)
- y축: 성능 (accuracy 등)
- 관찰 포인트 :
- train 성능과 validation 성능이 급격히 벌어지는 지점 찾기
- validaiton 성능의 고점
- 모델이 복잡해 지면, 가짜 패턴(혹은 연관성)까지 학습
- 가짜 패턴: 학습 데이터에만 존재하는 특이한 성질로 모집단의 특성이 아님! 학습 데이터 이외의 데이터셋에서는 성능이 떨어짐.
🧩 하이퍼 파라미터 실습
1. 하이퍼 파라미터 범위 지정
params = {
'max_depth': range(1, 16),
'min_samples_leaf': [10, 30, 50] # 리프노드에 포함될 최소 샘플 수
}2. 함수 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV3. 모델 선언
dt = DecisionTreeClassifier(random_state=0)
grid_dt = GridSearchCV(
estimator=dt,
param_grid=params, # 탐색할 하이퍼 파라미터 범위
cv=5, # 5-fold Cross Validation
scoring='accuracy',
n_jobs=-1 # 모든 CPU 코어 사용하여 연산 속도 향상
)4. 학습
grid_dt.fit(x_train, y_train)5. 최적의 하이퍼 파라미터
# 선택괸 best parameter
grid_dt.best_params_
# best parameter에서의 cv 성능
grid_dt.best_score_# 결과
np.float64(0.7025)6. 최종 모델로 예측 및 평가
best_model = grid_dt.best_estimator_ # Grdi Search로 선택된 최종 모델
pred = best_model.predict(x_val) # validaiton 데이터레 대해 예측 수행
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
accuracy_score(y_val, pred)
confusion_matrix(y_val, pred)
print(classification_report(y_val, pred))# 결과
precision recall f1-score support
LEAVE 0.67 0.78 0.72 3900
STAY 0.75 0.63 0.68 4100
accuracy 0.70 8000
macro avg 0.71 0.70 0.70 8000
weighted avg 0.71 0.70 0.70 8000
🧩 블로그 챌린지
[ BDAI 활동 후기 ]
9주차를 맞으면서 학회 활동의 절반이 지나갔다. 그만큼 강의 난이도도 올라가고 있지만 진도를 놓지지 않도록 열심히 따라가고 있다. 물론 블로그 안 빼먹고 작성 중이다! 16주차까지 잘 끝내는 게 목표이다.
휴회기간 전 마지막으로 내주셨던 과제 채점도 나왔던데 강사님이 피드백까지 적어주셔서 너무 감사했다! 마지막까지 화이팅이드아
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 모델링 실습 (0) | 2026.01.06 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 (0) | 2026.01.05 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 8주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 5주차 (0) | 2026.01.04 |