지도학습 기본 알고리즘 - 선형회귀
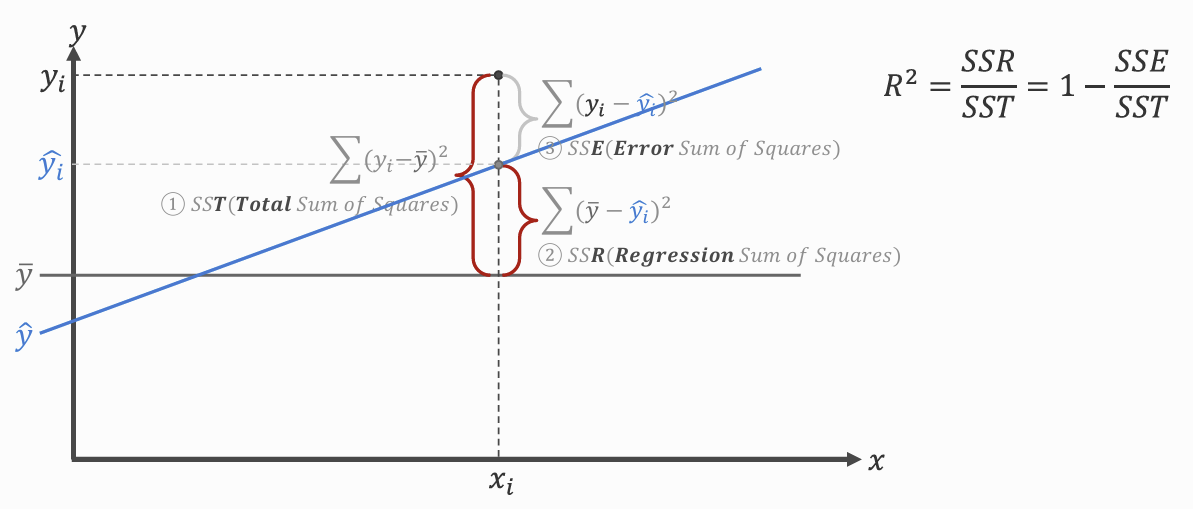
오차의 비로 평가하기 - R²
평균 모델의 오차와 회귀모델 오차
- 평균 모델과 실제 값의 차이 - SST
- 평균 모델과 회귀 모델과의 차이 - SSR
- 실제 값과 회귀 모델과의 차이 - SSE
오차 해결율: R²-squared
- 평균 모델의 오차 대비 회귀 모델이 해결한 오차의 비율(= 결정계수, 설명력)
- 회귀 모델이 얼마나 오차를 해결했는지?
오차의 양과 율로 평가하기
오차 계산
| 실제값 | 예측값 | Error | MSE | MAE | MAPE |
|---|---|---|---|---|---|
| y | ŷ | y - ŷ | (y - ŷ)² | |y - ŷ| | |y - ŷ|/y |
| 6 | 4 | 2 | 4 | 2 | 2/6 |
| 5 | 6 | -1 | 1 | 1 | 1/5 |
| 12 | 9 | 3 | 9 | 3 | 3/12 |
| 2 | 2 | 0 | 0 | 0 | 0 |
오차의 평균 계산
- Sum Squared Error (SSE) = 14
- Mean Squared Error (MSE) = 14 / 4 = 3.5
- Root MSE (RMSE) = sqrt(3.5) ≈ 1.8708286934
- Mean Absolute Error (MAE) = (2+1+3+0) / 4 = 6 / 4 = 1.5
- Mean Absolute Percentage Error (MAPE) = (0.333333 + 0.2 + 0.25 + 0) / 4 = 0.1958333 ≈ 19.58333%
다중회귀(Multiple Linear Regression)
다중 회귀
- feature가 2개 이상인 선형 회귀 모델
- feature은 서로 독립적이어야 함!
e.g. y = 3.5*x1 + 8.22*x2 - 9*x + 0.21
다중 공선성(Muti-Collinearity)
- 선형회귀, 로지스틱회귀 모델에서 발생하는 문제
- 공선성(Collinearity): 하나의 독립변수가 다른 독립변수와 높은 상관관계를 가짐
- 다중 공선성(Multicollinearity): 여러 독립변수가 다른 하나의 독립변수를 설명할 수 있을 만큼 강한 상관관계가 존재하는 경우
다중 공선성 문제점
- 회귀 계수(가중치, 파라미터) 추정이 불안정해짐
- 데이터가 약간 변해도 추정치가 크게 달라짐
- 계수가 통계적으로 유의미하지 않게 됨
- 해석력 저하(어떤 변수가 실제로 중요한지 판단 어려움)
ex)
확인 방법 - 분산 팽창 지수(VIF, Variance Inflation Factor)
일반적으로 VIF > 10 -> 다중 공선성 문제 의심
But, 다중 공선성으로 항상 성능 문제가 발생되는 것은 아님. 다중 공선성은 선형회귀 모델에서만 발생! -> 현직에서는 필요도 낮음.
규제 (Regularization)
- 다중 공선성 -> 회귀 계수가 불안정해짐
- 해결 방법: 규제(제약)를 가해서 회귀 계수 크기를 제한
릿지(Ridge)
- 계수의 제곱합을 규제
- L2규제: 전체 계수를 작게(shrinkage) 시킴
라쏘(Lasso)
- 계수의 절댓값 합을 규제
- L1규제: 일부 계수를 아예 0으로 만들어 변수 제거
모델링
1. 환경준비
# 데이터 다루는 라이브러리
import numpy as np
import pandas as pd
# 데이터 시각화 라이브러리
import matplotlib.pyplot as plt
# 머신러닝 라이브러리
from sklearn.model_selection import train_test_split # 데이터 분할
from sklearn.metrics import * # 모델 평가 함수들 전체(*)
from sklearn.linear_model import LinearRegression2. 데이터 준비
(1) 데이터분할: x, y 나누기
target = 'Sales'
x = data.drop(target, axis=1)
y = data.loc[:, target](2) 가변수화
cat_cols = ['ShelveLoc', 'US','Urban']
# 첫번째 가변수 제거
x = pd.get_dummies(x, columns=cat_cols, drop_first=True)
x.head()(3) 데이터분할: train: validaiotn 나누기
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random_state = 20)3. 모델링 - 다중회귀
model1: Price+Age만 이용하여 모델링하기
(1) 변수 지정
features = ['Price','Age' ]
x_train1 = x_train[features] # 지정한 변수 리스트를 train1 셋에 넣음
x_val1 = x_val[features](2) 선형회귀 모델
model1 = LinearRegression()
model1.fit(x_train1, y_train)(3) 계수 확인하기
print(list(x_train1)) # column 이름으로 한 리스트를 보여줌
print(model1.coef_, model1.intercept_)(4) 오차율 구하기
print('RMSE :', root_mean_squared_error(y_val, pred1)) # 오차율이니까 작을수록 좋음
print('MAE :', mean_absolute_error(y_val, pred1))
print('r2 :', r2_score(y_val, pred1)) # 오차해결율이니까 클수록 좋음오차율 비교하기
feature 2개만 고려한 모델
RMSE : 2.5176666485070442
MAE : 2.053592574723096
r2 : 0.23901833455873955전체 변수를 고려한 모델
RMSE : 1.1271151463198543
MAE : 0.9415085484647864
r2 : 0.8474843845917948
여러 개의 변수를 고려한 모델의 R2 score가 높은 것으로 보아 더 많은 변수를 고려할수록 정확도가 올라간다는 것을 알 수 있다.
3주차 블로그 챌린지🔥
현재 3주차까지 빅데이터 분석 학회(BDA 학회) 수업을 들으며 느낀점을 정리해보려 한다. 나는 매주 목요일 오후 10시부터 11시까지 강의를 듣고 있는데 평소 생활 패턴이나 아르바이트 시간에 크게 방해받지 않고 저녁 시간에 수업을 들을 수 있어서 만족스러웠다.
강사님이 개념부터 차근차근 설명해주시고 중간에 너무 빠른 것 같으면 학생들에게 설명이 한 번 더 필요한지 여쭤봐 주신다. 중간중간 질문에도 잘 답해주시고 흥미로운 예시나 현직 이야기도 풀어주셔서 강의도 정말 재밌게 잘 듣고 있다.
강의가 끝난 후에는 녹화본을 시청할 수 있고, 강사님이 준비해주신 자료로 복습도 할 수 있다. 복습용 과제가 있긴 하지만 크게 부담스럽지 않고 내용을 정리할 수 있는 수준이라 딱 좋았다.
또한 지난주에는 원데이 클래스를 신청해 수강했다. 색다른 주제를 체험형으로 접할 수 있다는 점은 장점이었으나 강의 진행 방식이나 흐름에서 다소 아쉬움이 남았다. 그럼에도 전반적으로 유익한 시간이었다. 앞으로는 대면 클래스도 생기면 좋겠다고 생각한다.
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 6주차 (0) | 2026.01.04 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 5주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 4주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 2주차 (0) | 2026.01.04 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 1주차 (0) | 2026.01.04 |