🧊 차원축소 (Dimensionality Reduction)
1. 패턴을 찾는 방법
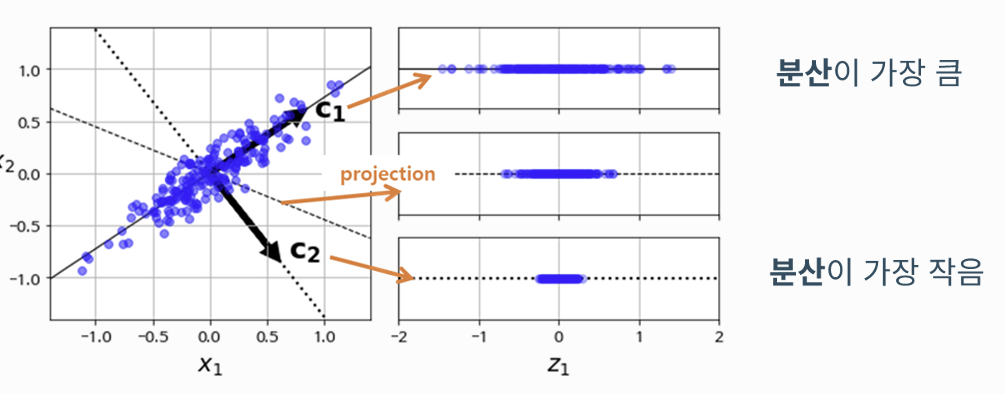
- 각 점은 하나의 관측치(sample)
- 전체 분포가 가지는 패턴을 찾는 것이 핵심
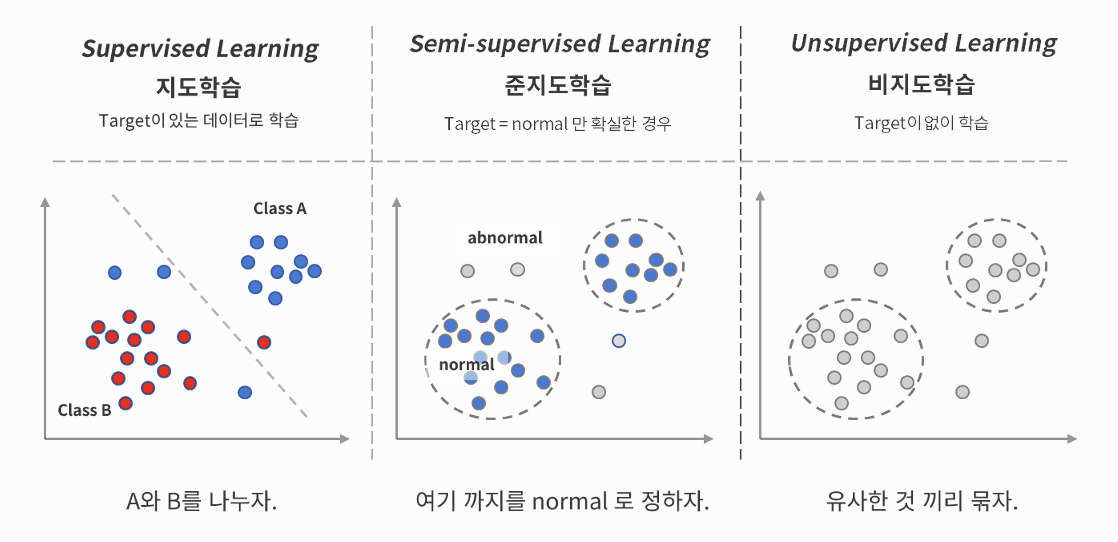
2. 비지도 학습 특징
- 정답 레이블(y) 없이 입력 변수 x만 사용 → x 안에서 패턴 인식 문제
- 데이터 내부 구조, 분포, 관계를 스스로 학습
- 단독으로 끝내기보다는 후속 분석을 위한 전처리 단계로 사용하는 경우가 많음
(1) 비지도 학습의 주요 활용 방식
- 차원축소 : 고차원 데이터를 축소하여 새로운 feature를 생성 → 시각화, 지도학습 연계
- 클러스터링 : 고객별 군집 생성 → 고객 세그먼트 분석, 패턴 그룹화
- 이상탐지 : 정상 데이터 범위 지정 → 범위 밖 데이터를 이상치로 판정
(2) 차원(dimension)
- 차원의 수 = 변수(feature)의 수
- 변수가 많아질수록 → 표현력 증가 & 모델 복잡도 증가
- ❗BUT, 변수를 계속 추가하다 보니 중요하지 않은 변수가 포함되기도 하고 오히려 방해가 될 수도 있음 + 불필요하게 복잡한 데이터
👉 결과적으로 데이터가 희박(sparse) 해지는 문제가 발생
3. 희박한(Sparse) 데이터

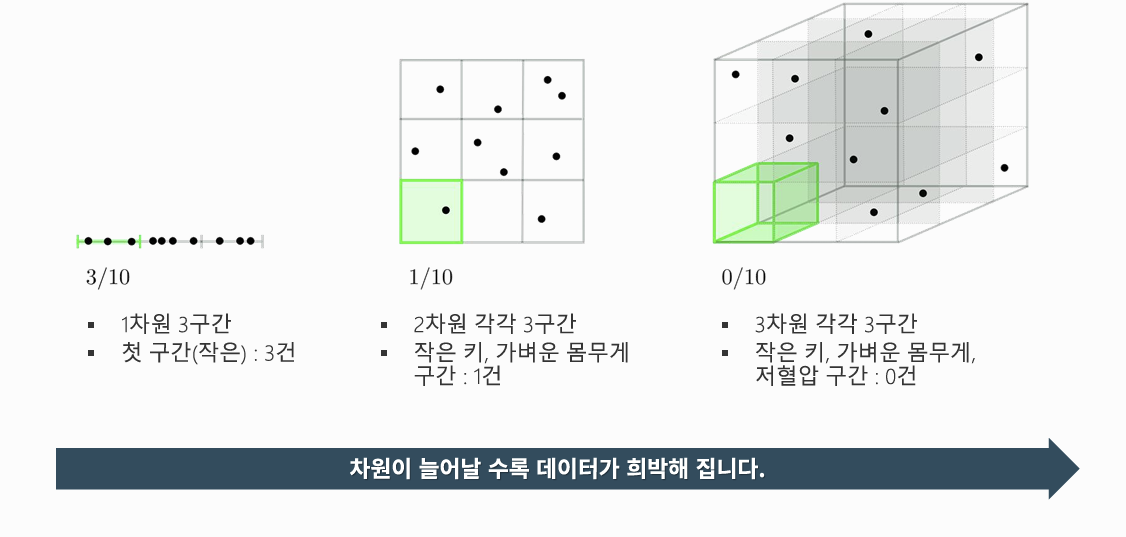
4. 차원의 저주(Curse of Dimension)
차원이 증가할수록 발생하는 문제들을 통칭하여 차원의 저주라고 부름.
변수가 많아지면 조건에 맞는 데이터가 희박해짐 → 학습이 적절하게 되지 않을 가능성이 높아짐
고차원 문제의 본질은 대부분 희박성 문제로 귀결됨
해결방안
- 행을 늘리기 → 데이터 늘리기 (현실적으로 비용이 큼)
- 열을 줄이기 → 차원 축소 (현실적인 방법)
5. 해결방안: 차원 축소
- 다수의 feature(고차원) → 새로운 소수의 feature(저차원)로 축소
- 기존 특성을 최대한 유지
- 목적: 계산량 감소, 노이즈 제거, 과적합 방지, 시각화 가능
- *대표적인 방법: *
- (1) 주성분 분석(PCA)
- (2) t-SNE

6. 주성분 분석 (PCA: Principal Componet Analysis)
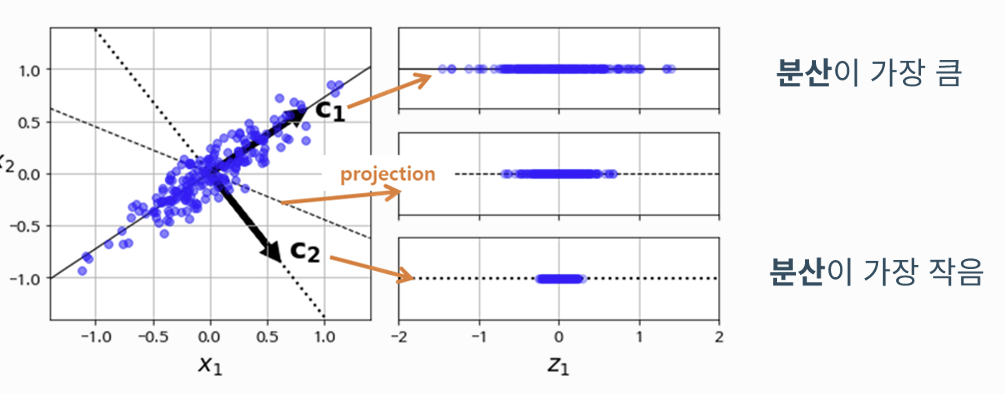
(1) 주성분 분석의 직관적 의미
- 변수(차원)의 수보다 적은 저차원의 평명으로 투영(Projection)

- 위의 이미지는 3차원 데이터가 2차원 평면으로 투영되는 과정을 보여줌.
- 투영 후에도 원 데이터의 가장 많은 정보를 담고 있는 방향으로 투영해야함.
(2) 모델에 적용해보기
| 원본 모델 | 어떤 평면으로 투영시킬 것인가? |
|---|---|
 |
 |
(3) 주성분 분석 절차
- 학습 데이터셋에서 분산이 최대인 첫 번째 축을 탐색
- 첫 번째 축과 직교(orthogonal)하면서 분산이 최대인 두 번째 축을 탐색
- 첫 번째 축과 두 번째 축에 직교하고 분산이 최대인 세 번째 축을 탐색
- 1~3번과 같은 방법으로 데이터셋의 차원만큼의 축을 탐색
- 각 축의단위벡터를 주성분(Principal Components)이라고 부름.
- 각 데이터는 주성분 축으로 투영된 좌표값을 가짐.
7. PCA 사용하기
(1) 전처리: 스케일링 필요
- PCA는 분산 기반 기법
- 주성분 결정 시 분산 비교(크기 비교)
- 스케일링 없이 PCA 수행 → 스케일이 가장 큰 변수에 영향을 가장 많이 받게 됨
(2) PCA 문법
- 선언: 주성분의 개수(n) 지정
- 적용: x_train으로 fit & transform
- 결과는 numpy array가 됨
# 주성분 분석 선언
pca = PCA(n_components=n)
# 만들고 적용하기
x_train_pc = pca.fit_transform(x_train)
x_val_pc = pca.transform(x_val)- 주성분의 개수 정하기: 주성분의 개수를 늘려가면서 원본 데이터 분산과 비교 → Elbow Method
plt.plot(range(1,n+1), pca.explained_variance_ratio_, marker = '.')
plt.xlabel('No. of PC')
plt.grid()
plt.show()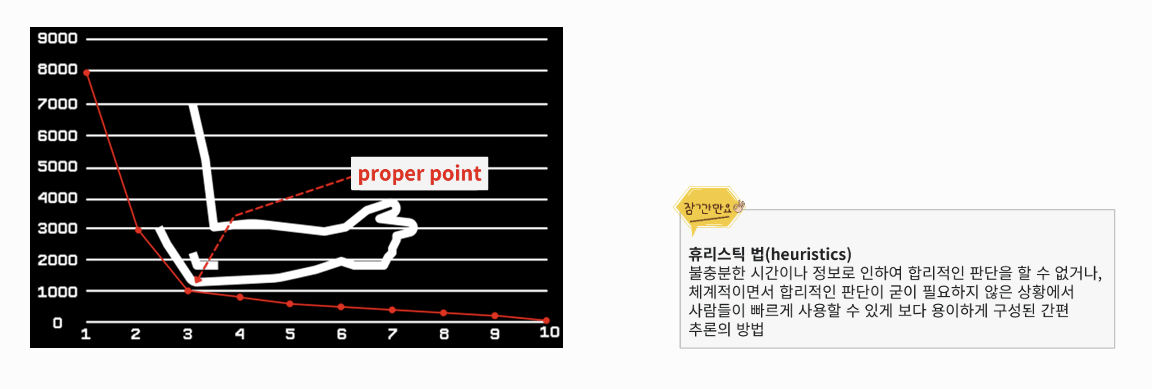
- Elbow Method: 팔꿈치 지점 근방에서 적절한 값을 찾는 것
🧊 차원축소 모델링 실습
1. 환경준비
(1) 라이브러리 로딩
!pip install plotly -q
import plotly.graph_objects as go
# 기본 라이브러리 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import *
from sklearn.datasets import load_breast_cancer, load_digits, load_iris, make_swiss_roll
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA(2) 샘플 데이터 생성하기
# 럭비공 형태의 샘플 데이터 생성 함수
def generate_rugby_data(n_points=1000, a=1, b=1.5, c=2):
phi = np.random.uniform(0, np.pi, n_points)
theta = np.random.uniform(0, 2*np.pi, n_points)
x = a * np.sin(phi) * np.cos(theta)
y = b * np.sin(phi) * np.sin(theta)
z = c * np.cos(phi)
X = np.column_stack((x, y, z))
return X
rugby = generate_rugby_data()
# 스위스롤 데이터
swiss_roll, _ = make_swiss_roll(n_samples=1000, noise=0.2)# 3차원 스캐터 함수 생성
def my_3d_Scatter(X) :
fig = go.Figure()
fig.add_trace(go.Scatter3d(x=X[:, 0], y=X[:, 1], z=X[:, 2],
mode='markers', marker=dict(size=2, color='blue'),
name='Original Data'))
fig.update_layout(margin=dict(l=0, r=0, b=0, t=0),
scene=dict(xaxis_title='X Axis', yaxis_title='Y Axis', zaxis_title='Z Axis'))
fig.show()2. PCA 연습해보기
(1) 럭비공 형태의 데이터 차원 축소
# 럭비공 데이터 3D 시각화 확인
my_3d_Scatter(rugby)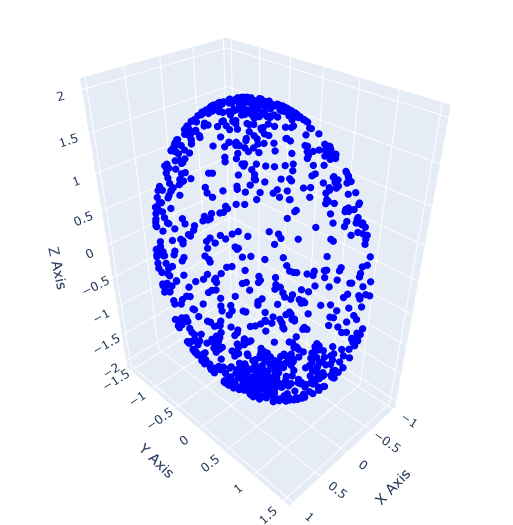
# PCA를 이용하여 2개의 주성분으로 차원 축소
pca = PCA(n_components=2)
X_pca = pca.fit_transform(rugby)
# PCA 축소 데이터 조회
plt.scatter(X_pca[:, 0], X_pca[:, 1])
plt.grid()
plt.show()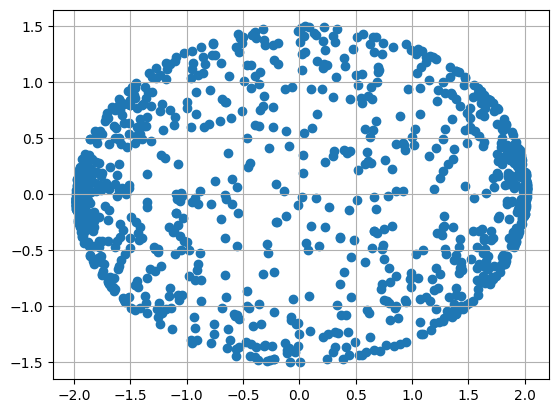
(2) 스위스롤 형태의 데이터 차원 축소
my_3d_Scatter(swiss_roll)
# PCA를 이용하여 2개의 주성분으로 차원 축소
pca = PCA(n_components=2)
X_pca = pca.fit_transform(swiss_roll)
# PCA 축소 데이터 조회
plt.scatter(X_pca[:, 0], X_pca[:, 1])
plt.grid()
plt.show()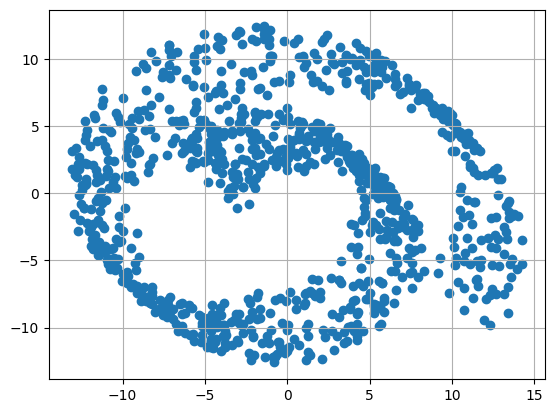
3. PCA 사용해보기
(1) 데이터 준비
iris = pd.read_csv("https://raw.githubusercontent.com/DA4BAM/dataset/master/iris.csv")
target = 'Species'
x = iris.drop(target, axis = 1)
y = iris.loc[:, target]- 스케일링
scaler = MinMaxScaler()
x2 = scaler.fit_transform(x)
# (옵션)데이터프레임 변환
x2 = pd.DataFrame(x2, columns= x.columns)(2) 주성분 분석
from sklearn.decomposition import PCA
# feature 수
x2.shape[1] # 4- 주성분 분석 수행
# PCA 수행 (4차원 -> 2차원)
n = 2
pca = PCA(n_components = n)
x2_pc = pca.fit_transform(x2) # 결과는 numpy array 형태
# 2개의 주성분
x2_pc[:5]# 원본 데이터와 주성분(PC1, PC2) 비교를 위해 병합
pd.concat([iris, x2_pc], axis = 1).head()- 두 개의 주성분 시각화
sns.scatterplot(x = 'PC1', y = 'PC2', data = x2_pc, hue = y)
plt.grid()
plt.show()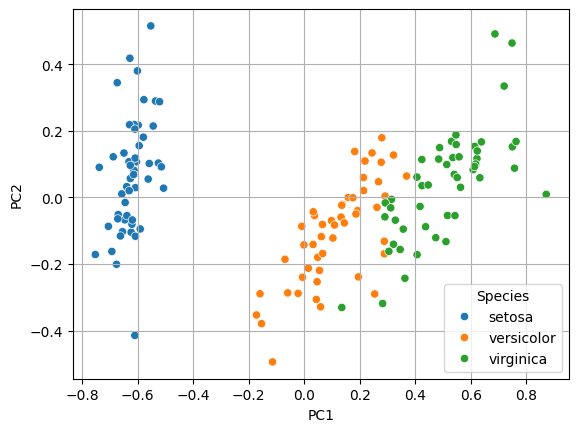
4. 고차원 데이터 차원축소
(1) 데이터 로딩
# breast_cancer 데이터 로딩
cancer=load_breast_cancer()
x = cancer.data
y = cancer.target
x = pd.DataFrame(x, columns=cancer.feature_names)
x.shape(2) 스케일링
- 거리계산 기반 차원축소이므로 스케일링 필요
scaler = MinMaxScaler()
x = scaler.fit_transform(x)
# (옵션)데이터프레임 변환
x = pd.DataFrame(x, columns=cancer.feature_names)(3) 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random_state = 20)(4) 주성분 만들기
from sklearn.decomposition import PCA
# feature 수
x_train.shape[1] #30- 주성분 분석 수행
# 주성분을 몇개로 할지 결정(최대값 : 전체 feature 수)
n = x_train.shape[1]
# 주성분 분석 선언
pca = PCA(n_components=n)
# 만들고, 적용하기
x_train_pc = pca.fit_transform(x_train)
x_val_pc = pca.transform(x_val)- 편리하게 사용하기 위해 데이터프레임으로 변환
# 칼럼이름 생성
column_names = [ 'PC'+str(i+1) for i in range(n) ]
column_names# 데이터프레임으로 변환하기
x_train_pc = pd.DataFrame(x_train_pc, columns = column_names)
x_val_pc = pd.DataFrame(x_val_pc, columns = column_names)
x_train_pc5. 조건에 맞게 주성분 추출해서 비교하기
Q. 다음의 조건으로 주성분을 추출해 보자.
- 주성분 1개로 선언하고, x_train을 이용해서 주성분 추출
- 주성분 2개로 선언하고, x_train을 이용해서 주성분 추출
- 주성분 3개로 선언하고, x_train을 이용해서 주성분 추출
(1) 개수에 맞는 주성분 추출
# 주성분 1개짜리
pca1 = PCA(n_components=1)
x_pc1 = pca1.fit_transform(x_train)
# 주성분 2개짜리
pca2 = PCA(n_components=2)
x_pc2= pca2.fit_transform(x_train)
# 주성분 3개짜리
pca3 = PCA(n_components=3)
x_pc3= pca3.fit_transform(x_train)- 각 주성분 결과에서 상위 3개 행씩 조회하여 비교해 보자.
# 상위 3개 데이터만 찍어서 차원이 늘어나는 것(칼럼 수 증가)을 확인
print(x_pc1[:3])
print('-'*50)
print(x_pc2[:3])
print('-'*50)
print(x_pc3[:3])- 주성분 누적 분산 그래프
- x축: PC 수 / y축: 전체 분산크기 - 누적 분산크기
(2) 주성분 누적 분산 그래프
plt.plot(range(1,n+1), pca.explained_variance_ratio_, marker = '.')
plt.xlabel('No. of PC')
plt.grid()
plt.show()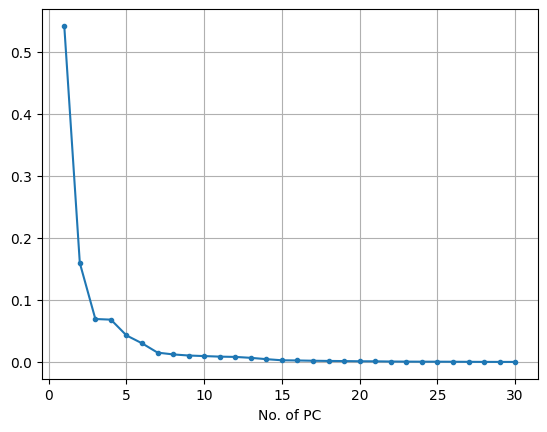
주성분 개수 3~4개면 충분하다 !!!!
(4) 시각화
sns.scatterplot(x = 'PC1', y = 'PC2', data = x_train_pc, hue = y_train)
plt.grid()
plt.show()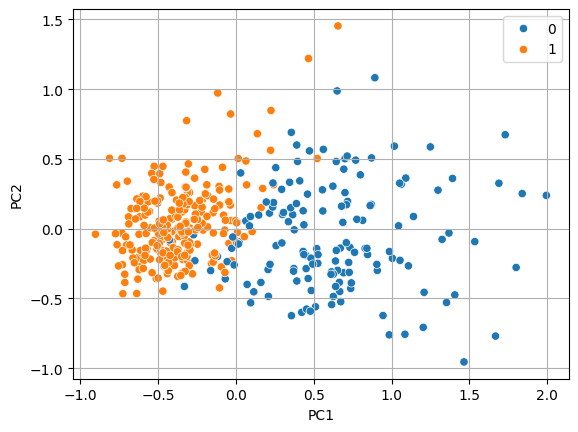
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 15주차 (0) | 2026.02.12 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 14주차 (0) | 2026.02.02 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 12주차 (1) | 2026.01.27 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 11주차 (0) | 2026.01.15 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 10주차 모델링 실습 (0) | 2026.01.06 |