
Ⅰ. 군집화: k-means, DBSCAN
1. k-means
개념
- K개의 평균으로부터 거리를 계산하고 가까운 평균으로 묶어 Cluster를 나누는 방식
k-means 절차
- 클러스터의 개수 지정(k)
- 그룹의 중심 점(mean)이 무작위로 선택됨
- 임의로 선택된 중심 점과 각 점 간의 거리를 계산해서 가장 가까운 중심점의 그룹으로 선택됨
- 선택된 그룹의 점들을 기준으로 중심점을 계산해서 찾고,
- 3~4번을 반복 → 중심점의 변화가 거의 없을 때까지 진행
k-meams 문법
- k-meas 함수 사용
- 거리 기반 알고리즘이어서 Scaling 필수
- k: n_clusters
- n_init : 초기값 무작위 지정, 지정된 회수 만큼 수행
- 학습할 때는 x만 입력
- 예측: 지정한 클러스터의 개수 내에서 구분
# k means 학습
model = KMeans(n_clusters= 2, n_init = 'auto')
model.fit(x)
# 예측
pred = model.predict(x)
print(pred)
2. k-means에서 적정 k값 찾기(1)
- 클러스틔 개수(k)를 어떻게 지정해 줄 것인가
- Inertia value : 군집화가 된 후에, 각 중심점에서 군집의 데이터 간의 거리를 합산한 값
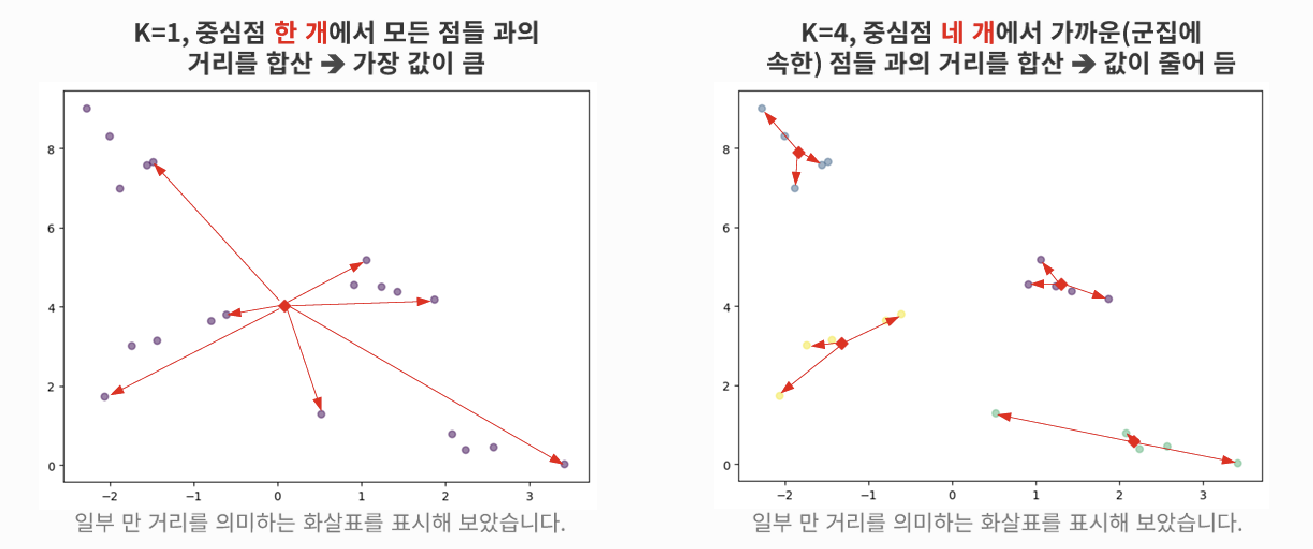
- 클러스터의 개수(k)를 증가시키면서 Inertia value를 뽑고, 적정 k값 찾기 → Elbow Method
3. k-means에서 적정 k값 찾기(2)
- 실루엣 점수: 클러스터링 겨로가의 품질 측정 지표 (-1 ~ 1 사이 값)

- 주의사항: 실루엣 점수를 계산하려면 최소한 k가 2개 이상이어야 함
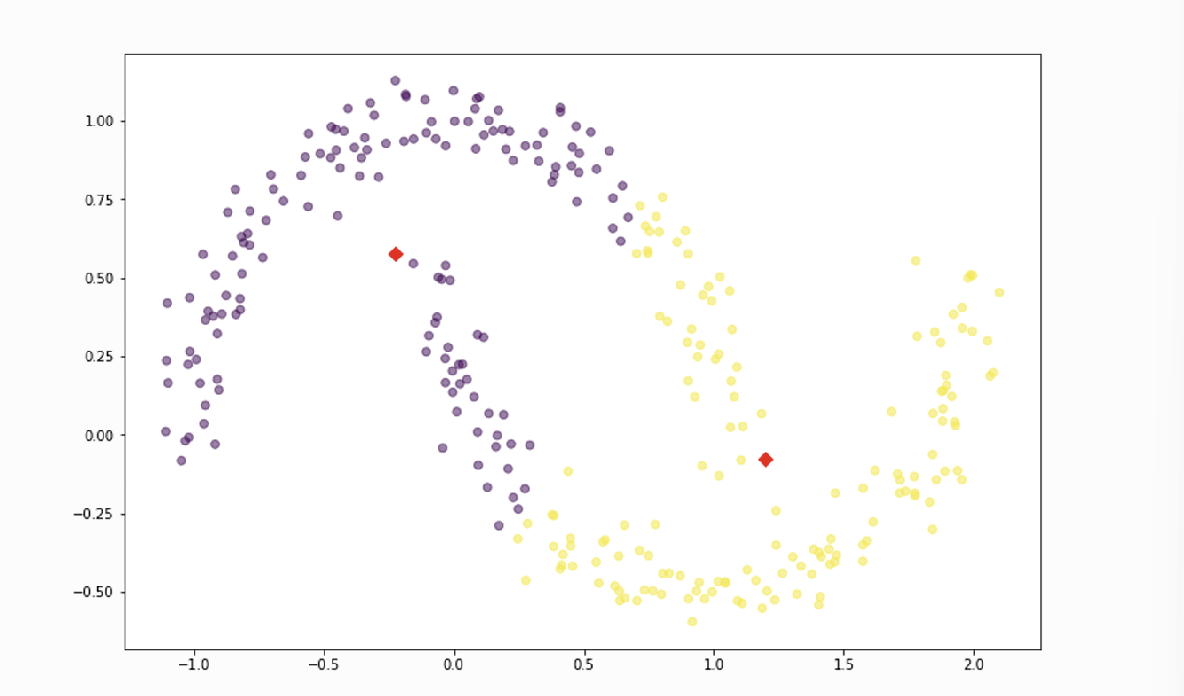
4. k-means의 단점
- k-means는 중심점에서의 거리로 군집화
- 볼록(convex)한 형태에서만 군집이 잘 형성됨
- 이러한 단점을 보완한 알고리즘이 DBSCAN
Ⅱ. DBSCAN
(Density-Based Spatial Clustering of Applications with Noise)
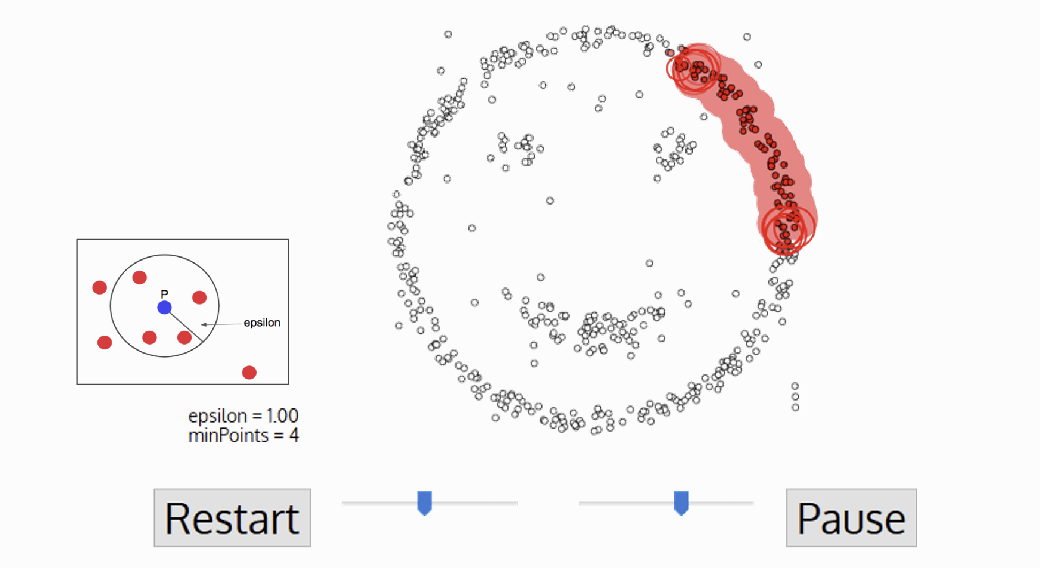
1. DBSCAN 절차
- 임의의 한 점으로부터 시작
- 반경 범위 내에 최소 포인트 수가 존재하는지 확인
- 존재한다면 각 포인트들을 중심으로 다시 원을 그어 최소 포인트 수 확인
- 2~3번 반복 수행
- 존재하지 않으면, 군집에 포함되지 않은 점으로 이동하여 1~4번 반복 수행
- 어느 군집에도 포함되지 않는 점은 이상치로 간주함.
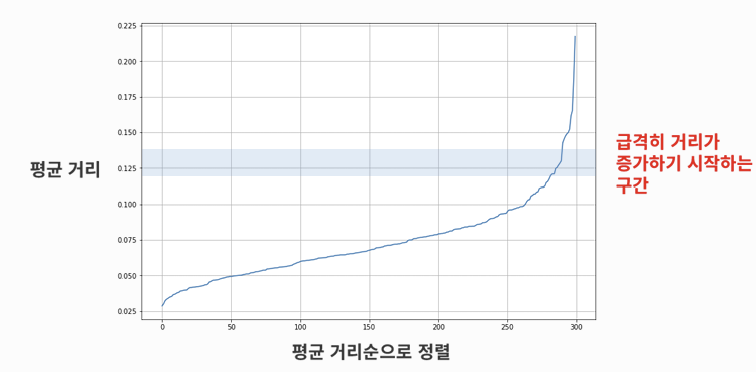
2. DBSCAN도 epsilon을 지정해줘야 한다
- KNN의 알고리즘으로부터 각 점과 근처 n개 점과 평균 거리 계산
- 거리 순으로 정렬하려 그래프 그리기
- 급격히 멀어지기 시작하는 거리 구간을 찾아 eps 값으로 적용
- elbow method 사용
k-means는 “거리 기반 평균 군집”(빠르고 단순하지만 구조에 약함), DBSCAN은 “밀도 기반 형태 군집”(느리지만 현실 데이터에 강함)
Ⅲ. 군집화 데이터 모델링
1. 환경준비
라이브러리 로딩
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
# 샘플데이터 로딩 함수
from sklearn.datasets import make_blobs, make_moons
# 클러스터링을 위한 함수
from sklearn.neighbors import NearestNeighbors
from sklearn.cluster import KMeans, DBSCAN
import warnings
warnings.filterwarnings("ignore", category=UserWarning)Sample Data
x, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
x = pd.DataFrame(x, columns = ['x1', 'x2'])
y = pd.Series(y, name = 'shape')
plt.figure(figsize = (8,6))
plt.scatter(x['x1'], x['x2'])
plt.show()
2. k-means
k-means 모델 만들기
# k means 학습
model = KMeans(n_clusters= 2, n_init = 'auto')
model.fit(x)
# 예측
pred = model.predict(x)
print(pred)
# feature + pred + y 붙여 놓고 비교
pred = pd.DataFrame(pred, columns = ['predicted'])
result = pd.concat([x, pred, y], axis = 1)
result.head()결과 시각화
# 모델의 중심 좌표 얻기
# k means 모델로 부터 클러스터의 평균 값들을 가져올 수 있음
centers = pd.DataFrame(model.cluster_centers_, columns=['x1','x2'])
centers# 시각화
plt.figure(figsize = (8,6))
plt.scatter(result['x1'], result['x2'], c = result['predicted'], alpha=0.5)
plt.scatter(centers['x1'], centers['x2'], s=50, marker='D', c='r')
plt.show()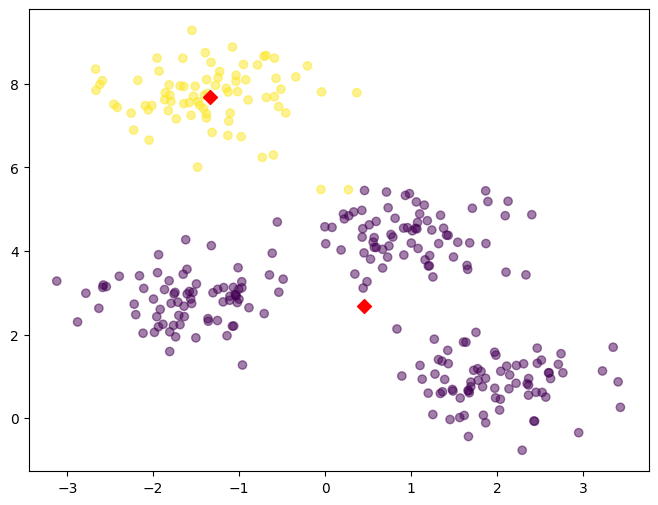
k 값에 따라 모델을 생성하고 그래프 그리기 함수
def k_means_plot(x, y, k) :
# 모델 생성
model = KMeans(n_clusters= k, n_init = 'auto')
model.fit(x)
pred = model.predict(x)
# 군집 결과와 원본 데이터 합치기(concat)
pred = pd.DataFrame(pred, columns = ['predicted'])
result = pd.concat([x, pred, y], axis = 1)
# 중앙(평균) 값 뽑기
centers = pd.DataFrame(model.cluster_centers_, columns=['x1','x2'])
# 그래프 그리기
plt.figure(figsize = (8,6))
plt.scatter(result['x1'],result['x2'],c=result['predicted'],alpha=0.5)
plt.scatter(centers['x1'], centers['x2'], s=50,marker='D',c='r')
plt.grid()
plt.show()적절한 K값 찾기
# k 값을 1~8까지 조절
k_means_plot(x, y, k = 1)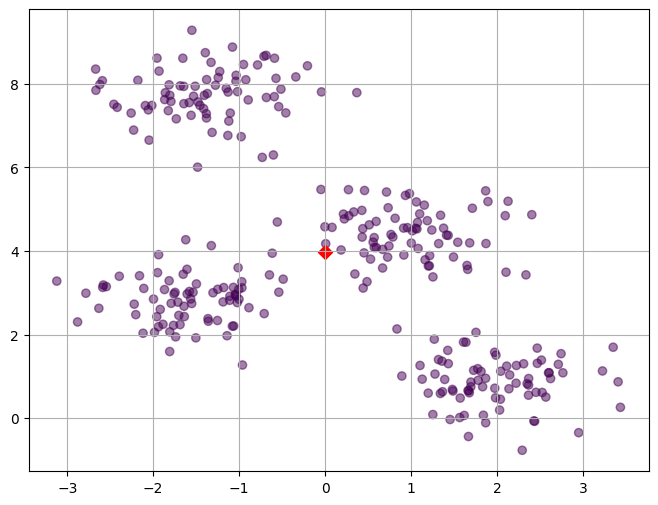
3. 적절한 k값 찾기① - inertia
- 눈으로 먼저 보니까 몇개로 군집화 할지 보이지만, 실전에서는 보고 판단할 수 없음
- k-means 모델을 생성하게 되면 inertia 값을 확인해서 결정할 수 있음
model.inertia_ # 1190.7823593643448# k를 증가시켜가면서 inertia 구하기
kvalues = range(1, 10)
inertias = []
for k in kvalues:
model = KMeans(n_clusters=k, n_init = 'auto')
model.fit(x)
inertias.append(model.inertia_)그래프 그리기
# Plot k vs inertias
plt.figure(figsize = (8, 6))
plt.plot(kvalues, inertias, marker='o')
plt.xlabel('number of clusters, k')
plt.ylabel('inertia')
plt.grid()
plt.show()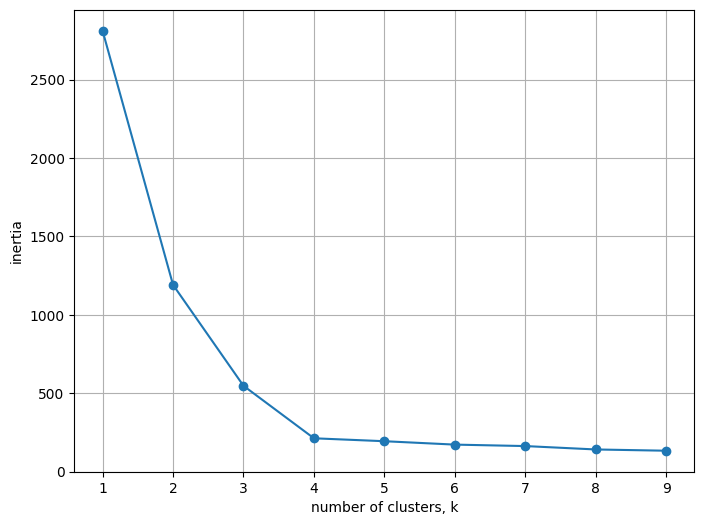
Elbow graph에서 k=4 지점 이후부터 inertia 감소폭이 급격히 줄어들기 떄문에, 적절한 군집 개수는 k=4이다
4. 적절한 k값 찾기② - 실루엣점수
from sklearn.metrics import silhouette_score
# 클러스터 개수에 따른 실루엣 점수를 저장할 리스트
kvalues = range(2, 10) # 최소 2개 이상이어야 함.
sil_score = []
for k in kvalues:
# KMeans 모델 생성
model = KMeans(n_clusters=k, n_init = 'auto')
# 모델을 학습하고 예측
pred = model.fit_predict(x)
# 실루엣 점수 계산
sil_score.append(silhouette_score(x, pred))# 실루엣 점수 시각화
plt.figure(figsize = (8, 6))
plt.plot(kvalues, sil_score, marker='o')
plt.xlabel('n_clusters')
plt.ylabel('Silhouette Score')
plt.grid()
plt.show()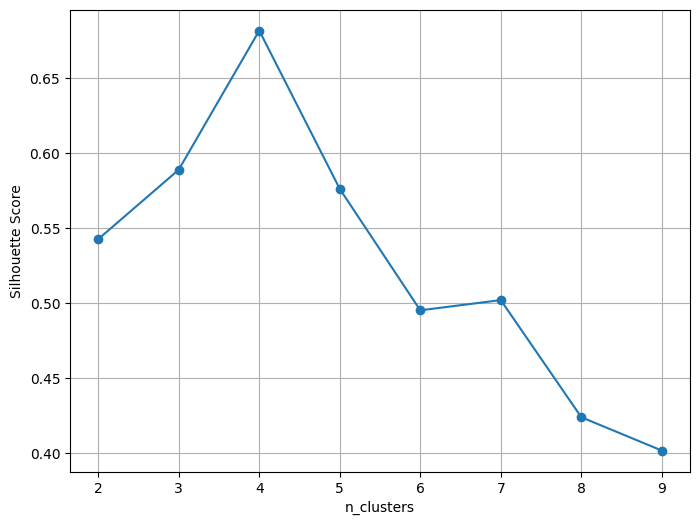
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 16주차 (0) | 2026.02.14 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 14주차 (0) | 2026.02.02 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 13주차 (0) | 2026.01.28 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 12주차 (1) | 2026.01.27 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 11주차 (0) | 2026.01.15 |