Ⅰ. 차원축소 t-SNE
1. PCA의 단점
- PCA는 분산이 가장 큰 방향을 기준으로 새로운 축을 찾는 선형 축소 방법, 계산이 빠르고 해석이 직관적
- But, 선형 구조만 표현 가능함
- 저차원에서 특징을 잘 담아내지 못하는 경우가 발생
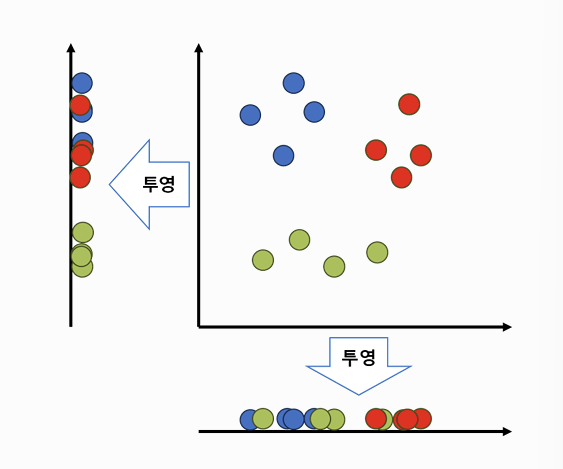
2. t-SNE (t-distributed Stochastic Neighbor Embedding)
- 원본(고차원 공간)에서 서로 가까운 데이터들끼리의 관계를 기반으로 유사도 맵을 생성
- 차원을 축소한 저차원 공강에서도 원본에서 가까웠던 데이터들이 여전히 가깝게 위치하도록 배치
⇒ 즉, 원본 데이터의 유사도 구조를 저차원에서도 유지하려는 차원 축소 방식!
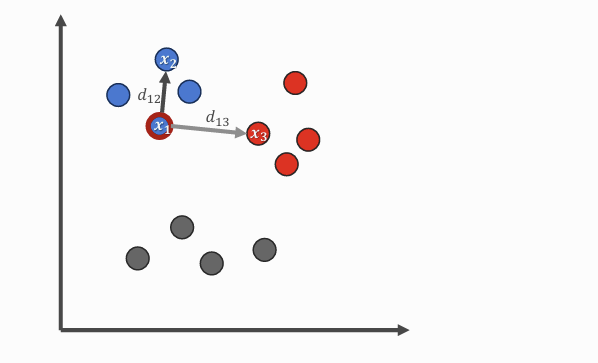
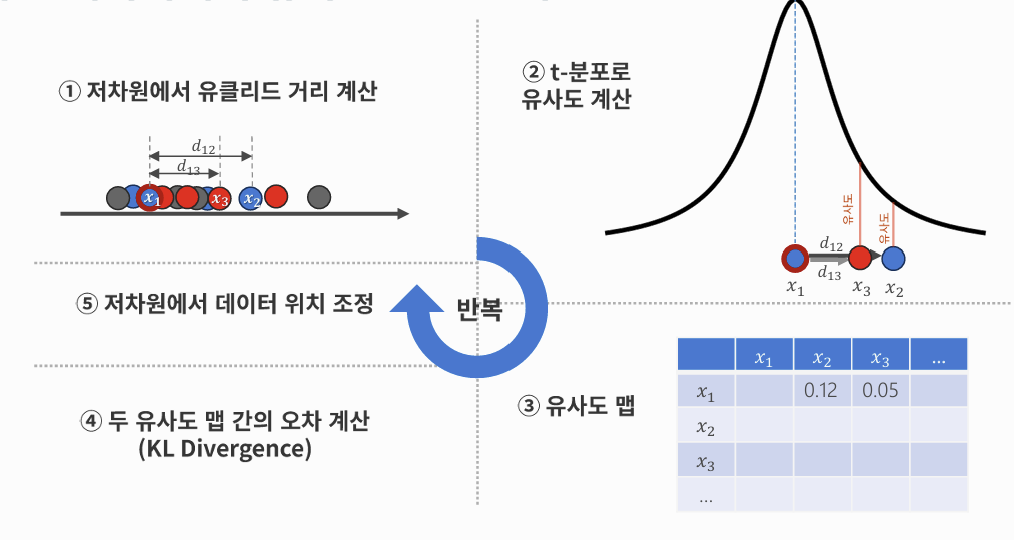
t-SNE 원리
- 원본 데이터에서 유클리드 거리 계산 → 어떤 점들이 서로 가까운지 파악
- 거리 정보를 확률적 유사도로 변환 → 가까운 점일수록 높은 확률을 갖도록 유사도 계산
- 원본 데이터으 유사도 맵 생성 → 고차원 공간에서의 이웃 관계를 확률 분포 형태로 표현
- 저차원 공간에서도 유사도 맵 생성
- 두 유사도 맵 간의 오차 계산 (KL Divergence) → 원본 공간과 저차원 공간의 유사도 분포 차이를 측정
- 오차를 줄이는 방향으로 데이터 위치 조정
3. t-SNE 사용하기
- 전처리: 스케일링 (필수는 아니지만 하는 것을 권장)
- 학습:
- 고차원을 2~3차원으로 축소
- 주로 데이터 시각화를 위해 사용
- 학습하는데 오래 걸림
from sklearn.manifold import TSNE
# 2차원으로 축소하기
tsne = TSNE(n_components = 2)
x_tsne = tsne.fit_transform(x)PCA Vs. t-SNE

| 구분 | PCA | t-SNE |
|---|---|---|
| 차원 축소 방식 | 선형 | 비선형 |
| 기준 | 전체 분산 최대화 | 이웃 간 유사도 보존 |
| 보존하는 구조 | 전역 구조 | 국소 구조 |
| 거리 해석 | 가능 | 불가 |
| 결과 안정성 | 높음 | 낮음 (초기값 영향) |
| 속도 | 빠름 | 느림 |
| 주요 목적 | 차원 축소, 전처리 | 데이터 시각화 |
Ⅱ. t-SNE 모델링 실습
1. 환경준비
(1) 라이브러리 로딩
# 기본 라이브러리 가져오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import *
from sklearn.datasets import load_breast_cancer, load_digits, load_iris, make_swiss_roll
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
2. 고차원 데이터 차원축소
종양 진단 데이터
(1) 데이터 준비
- 데이터 로딩
# breast_cancer 데이터 로딩
cancer=load_breast_cancer()
x = cancer.data
y = cancer.target
x = pd.DataFrame(x, columns=cancer.feature_names)
x.shape # (569, 30)- 스케일링: 거리계산 기반 차원축소이므로 스케일링 필요
scaler = MinMaxScaler()
x = scaler.fit_transform(x)
# (옵션)데이터프레임 변환
x = pd.DataFrame(x, columns=cancer.feature_names)- 데이터 분할
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random_state = 20)(2) 주성분 만들기
- 주성분 분석 수행
# 주성분을 몇개로 할지 결정(최대값 : 전체 feature 수)
n = x_train.shape[1]
# 주성분 분석 선언
pca = PCA(n_components=n)
# 만들고, 적용하기
x_train_pc = pca.fit_transform(x_train)
x_val_pc = pca.transform(x_val)- 편리하게 사용하기 위해 데이터프레임으로 변환
# 칼럼이름 생성
column_names = [ 'PC'+str(i+1) for i in range(n) ]
column_names# 데이터프레임으로 변환하기 - 중요도 순으로 정리한 칼럼
x_train_pc = pd.DataFrame(x_train_pc, columns = column_names)
x_val_pc = pd.DataFrame(x_val_pc, columns = column_names)
x_train_pc
# PC1 - 첫번째로 중요한 주성분
# PC2 - 두번째로 중요한 주성분 ...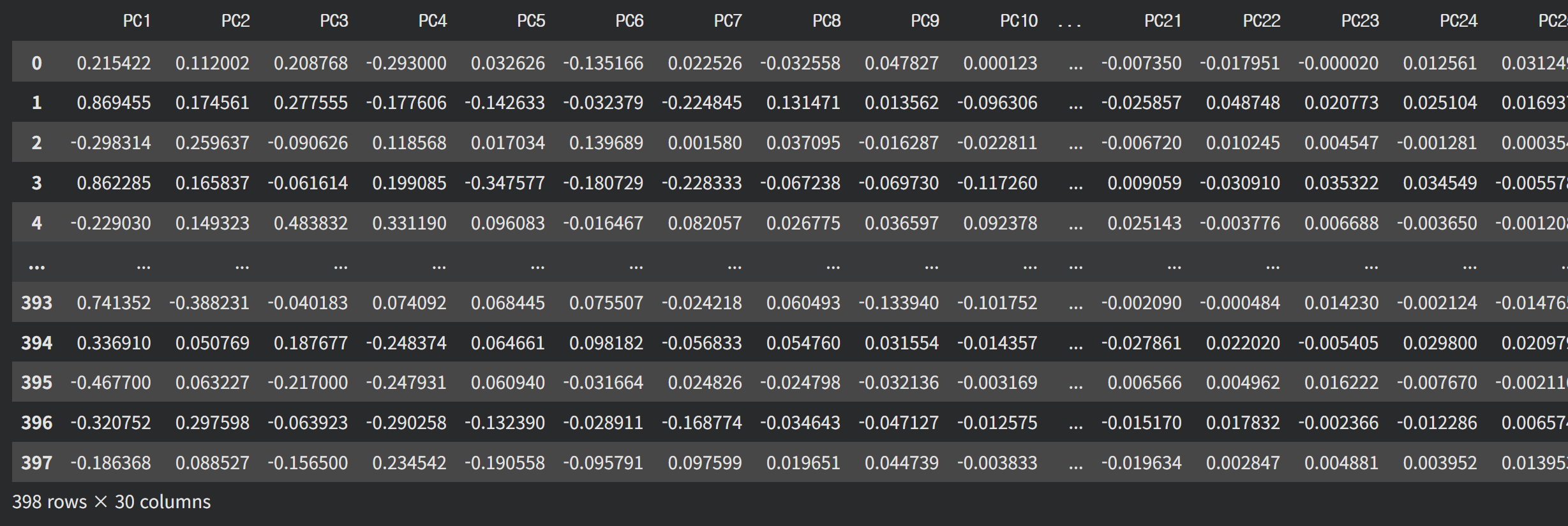
(3) 주성분 누적 분산 그래프
- 그래프를 보고 적절한 주성분의 개수를 지정(elbow method)
- x축: PC 수
- Y축: 전체 분산크기 - 누적 분산크기
plt.plot(range(1,n+1), pca.explained_variance_ratio_, marker = '.')
plt.xlabel('No. of PC')
plt.grid()
plt.show()
# Elbow 메소드 사용 - 3~7 사이의 값을 고르면 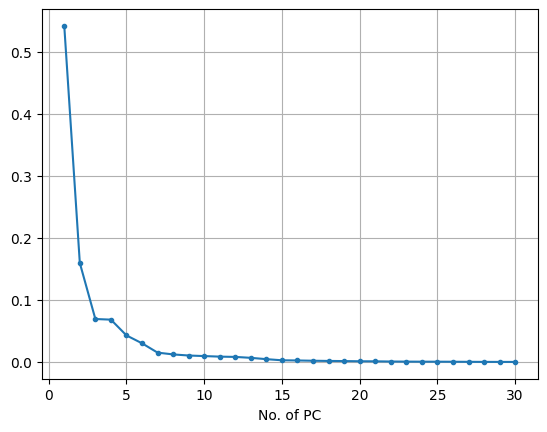
(4) 시각화
- 주성분 중 상위 2개를 뽑아 시각화
sns.scatterplot(x = 'PC1', y = 'PC2', data = x_train_pc, hue = y_train)
plt.grid()
plt.show()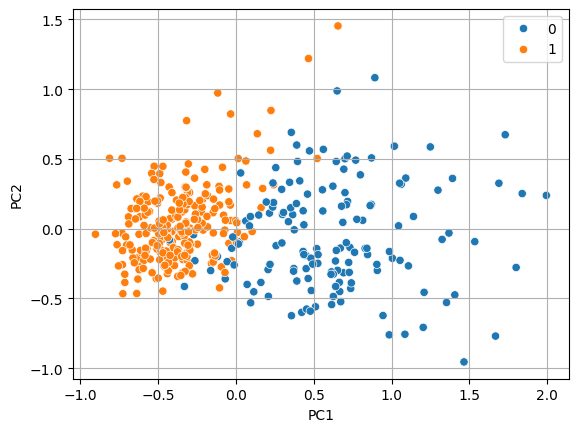
3. 지도학습으로 연계하기
(1) 원본 데이터로 모델 생성하기
- knn: 알고리즘으로 분류 모델링 수행
- k: 기본값으로 지정
# 학습
model0 = KNeighborsClassifier()
model0.fit(x_train, y_train)#예측 및 평가
# 원본데이터 모델의 성능
pred0 = model0.predict(x_val)
print(confusion_matrix(y_val, pred0))
print(accuracy_score(y_val, pred0))
print(classification_report(y_val, pred0, digits=4))[[ 62 2]
[ 3 104]]
0.9707602339181286
precision recall f1-score support
0 0.9538 0.9688 0.9612 64
1 0.9811 0.9720 0.9765 107
accuracy 0.9708 171
macro avg 0.9675 0.9704 0.9689 171
weighted avg 0.9709 0.9708 0.9708 171(2) PCA 후 모델링
knn 알고리즘으로 모델 만들고 성능 확인
column_names[:1]
cols = column_names[:1]
x_train_pc1 = x_train_pc.loc[:, cols] # pc1만 포함
x_val_pc1 = x_val_pc.loc[:, cols]
x_train_pc1.shape # (398, 1)(3) 주성분 1개로 만든 모델
# KNN 모델링, 주성분 1개로 모델링
model1 = KNeighborsClassifier()
model1.fit(x_train_pc1, y_train)# 원본데이터 모델의 성능
pred1 = model1.predict(x_val_pc1)
print(confusion_matrix(y_val, pred1))
print(accuracy_score(y_val, pred1))
print(classification_report(y_val, pred1))
# 성능: 0.9064327485380117(4) 주성분 2개로 모델링
n = 2
# 데이터 준비
cols = column_names[:n]
x_train_pc_n = x_train_pc.loc[:, cols]
x_val_pc_n = x_val_pc.loc[:, cols]
# 모델링
model_n = KNeighborsClassifier()
model_n.fit(x_train_pc_n, y_train)# 예측
pred_n = model_n.predict(x_val_pc_n)
# 평가
print(confusion_matrix(y_val, pred_n))
print(accuracy_score(y_val, pred_n))
print(classification_report(y_val, pred_n))
# 성능: 0.9649122807017544(5) 주성분 개수를 1~30개까지 늘려가면서 실험
result_acc = [] # 빈 리스트 생성
for n in range(1,31):
# 데이터 준비
cols = column_names[:n]
x_train_pc_n = x_train_pc.loc[:, cols]
x_val_pc_n = x_val_pc.loc[:, cols]
# 모델링
model_n = KNeighborsClassifier()
model_n.fit(x_train_pc_n, y_train)
# 예측
pred_n = model_n.predict(x_val_pc_n)
result_acc.append(accuracy_score(y_val, pred_n))plt.plot(range(1,31), result_acc, marker = '.')
plt.xlabel('No. of PC')
plt.grid()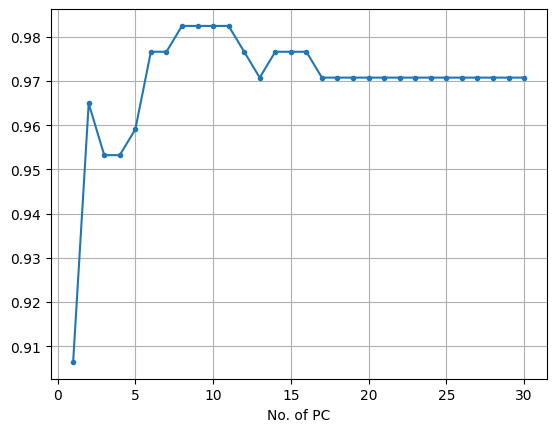
4. t-SNE - 종양 진단 데이터 차원축소
(1) 학습
from sklearn.manifold import TSNE # 후속작업: 시각화
# 2차원으로 축소하기
tsne = TSNE(n_components = 2, random_state=20)
x_tsne = tsne.fit_transform(x)
# 사용의 편리함을 위해 DataFrame으로 변환
x_tsne = pd.DataFrame(x_tsne, columns = ['T1','T2'])
x_tsne.shape # (569, 2)(2) 시각화
plt.figure(figsize=(6,6))
sns.scatterplot(x = 'T1', y = 'T2', data = x_tsne, hue = y)
plt.grid()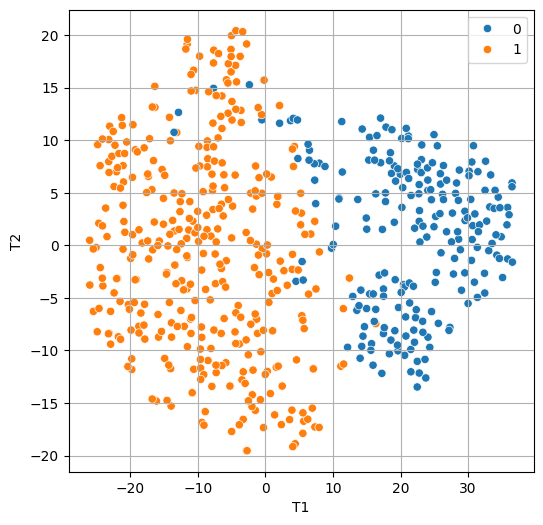
5. MNIST (슬림버전)
MNIST: 0부터 9까지의 손글씨 숫자로 구성된 대표적인 컴퓨터 비전 데이터셋
(1) 데이터 준비
digits = load_digits()
x = digits.data
y = digits.target
y = pd.Categorical(y) # 0~9 숫자를 범주형으로 명시적으로 지정
x.shape # (1797, 64)(2) 둘러보기
# f, axes = plt.subplots(5, 2, sharey=True, figsize=(16,6))
plt.figure(figsize=(10, 4))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x[i,:].reshape([8,8]), cmap='gray');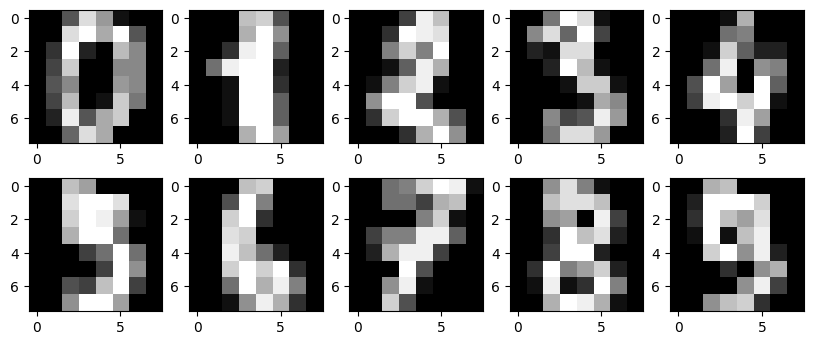
- 스케일링
# 최대, 최소값
np.min(x), np.max(x)
# 최대값으로 나누면 Min Max 스케일링이 됩니다.
x = x / 16(3) PCA
- 주성분 2개로 차원을 축소하고 시각화
# 차원 축소
pca = PCA(n_components=2)
x_pca = pca.fit_transform(x)
# 데이터프레임으로 변환(옵션)
x_pca = pd.DataFrame(x_pca, columns = ['PC1', 'PC2'])# 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(x = 'PC1', y = 'PC2', data = x_pca, hue = y)
plt.grid()
plt.show()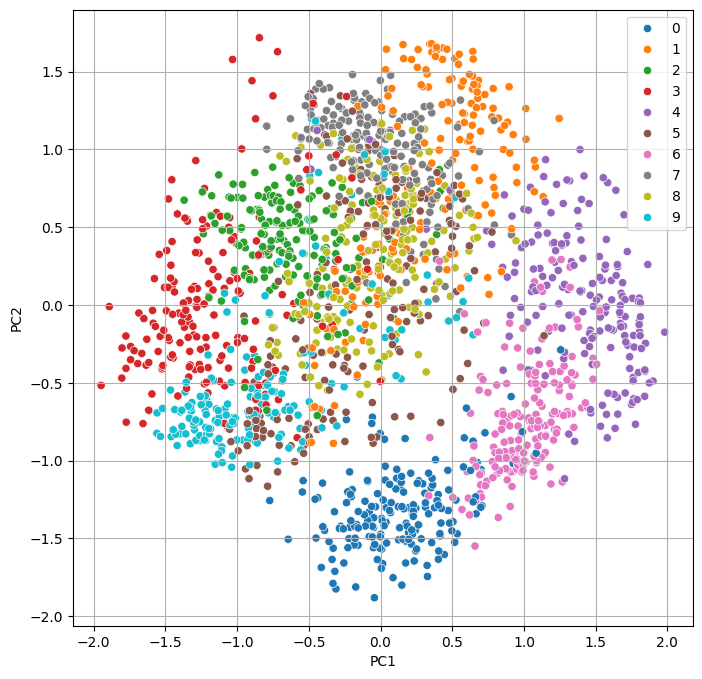
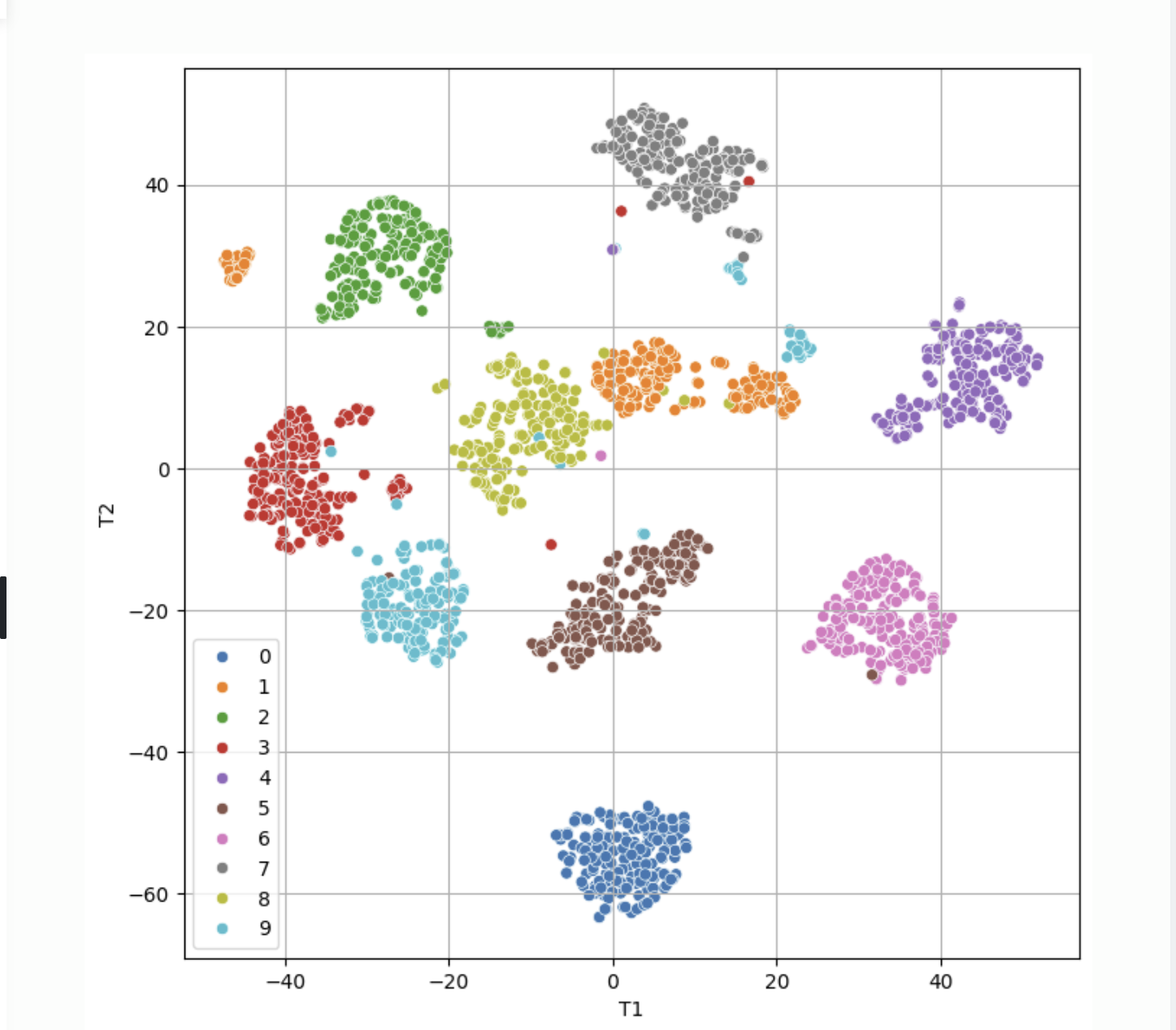
(4) tSNE
- 2차원으로 축소하고 시각화
tsne = TSNE(n_components = 2, random_state=20)
x_tsne = tsne.fit_transform(x)
# 데이터프레임으로 변환(옵션)
x_tsne = pd.DataFrame(x_tsne, columns = ['T1', 'T2'])# 시각화
plt.figure(figsize=(8, 8))
sns.scatterplot(x = 'T1', y = 'T2', data = x_tsne, hue = y)
plt.grid()
plt.show()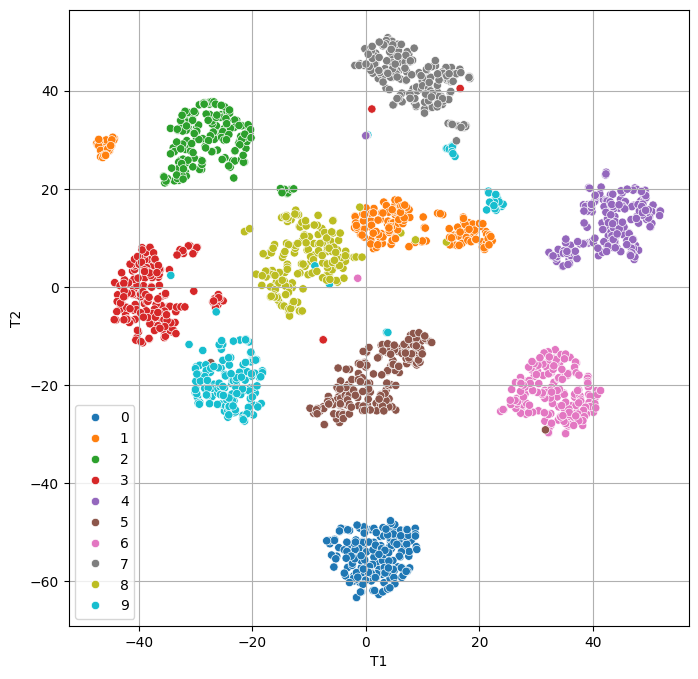
- tSNE 적용 후, 군집 형태로 명확하게 분리된 것을 확인할 수 있음
- 다만, 7과 9처럼 형태가 유사한 클래스는 일부 영역에서 섞여 나타남
- 이는 tSNE가 완벽한 분류 모델이 아니라, 유사도 기반 시각화 기법이기 때문
'BDA-11th' 카테고리의 다른 글
| [BDA 11기] 데이터 분석 모델링(ML1) - 16주차 (0) | 2026.02.14 |
|---|---|
| [BDA 11기] 데이터 분석 모델링(ML1) - 15주차 (0) | 2026.02.12 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 13주차 (0) | 2026.01.28 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 12주차 (1) | 2026.01.27 |
| [BDA 11기] 데이터 분석 모델링(ML1) - 11주차 (0) | 2026.01.15 |