🛸 기본 알고리즘 4 - 최근점 이웃(KNN)
KNN(k-Nearest Neighbor)
KKN은 거리 기반으로 예측하는 알고리즘으로, 예측하려는 점과 가장 가까운 K개의 이웃 데이터를 이용해 값을 결정한다.
1) 예측해야 할 데이터와 주어진 데이터의 모든 거리를 계산
2) 가까운 거리의 데이터를 K개 만큼 찾은 후
3) 회귀 또는 분류 문제인지에 따라 예측값을 계산
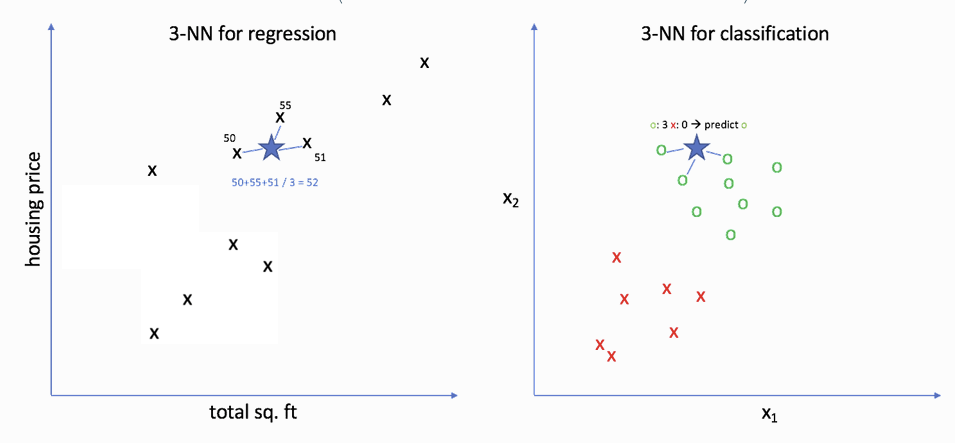
3-NN for Regression
- 연속적인 값 예측할 때 사용
(1) 데이터의 모든 거리를 계산
(2) 그 중에서 가장 가까운 3개를 선택
(3) 그 3개의 평균 -> 예측값
3-NN for Classification
- 가장 많이 등장한 클래스(다수결)을 예측
(1) 모든 거리를 계산
(2) 가장 가까운 3개를 선택
(3) 3개의 클래스 중 가장 많이 나타나는 클래스 선택
KNN 계산
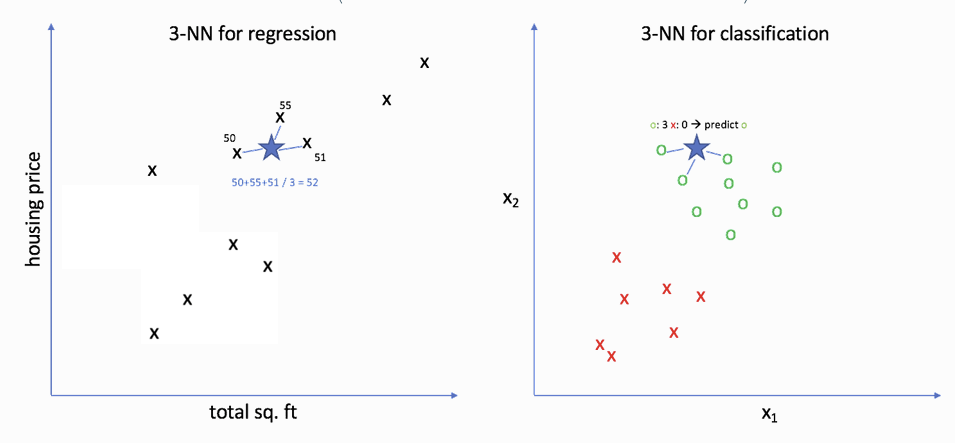
K값 결정
- K에 따라서 예측 결과가 달라짐
ex) K=3, K=6 - K의 최대값 = 이웃의 최대 개수
ex) 사진상 10개가 최대값 - K=1 일 때? -> 가장 가까운 이웃 하나만 계산
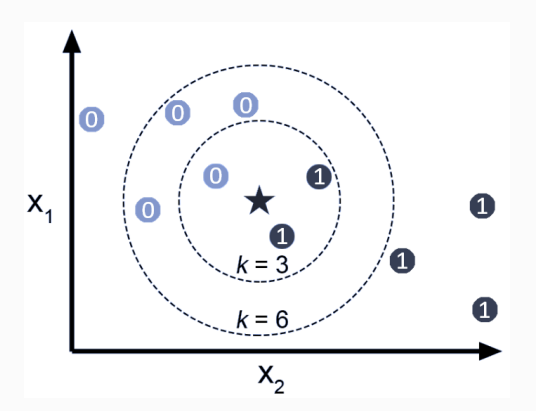
거리 계산 방법
유클리드 거리(Euclidean Distance)
- 두 점 사이의 직선 거리를 계산하는 방법 = 가장 짧은 거리
- 사진에서 점과 예측 데이터의 거리를 피타고라스로 계산
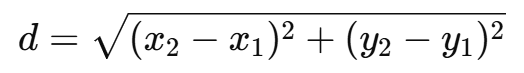
맨해튼 거리(Manhattan Distance)
- 두 점 사이의 거리를 직선이 아닌 가로/세로로만 이동했을 때의 거리
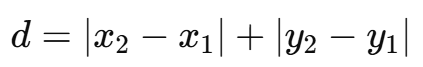
KNN을 위한 전처리: Scaling
Scaling이란?
- feature들 값의 범위와 단위가 각각 다름 -> 값의 범위가 큰 feature일수록 거리 계산에 많은 영향을 줌
- 이 값들을 맞춰주기 위해 전처리를 해야함
방법1: Normalization
입력변수 X가 [a,b] 범위라면 (a=min, b=max)
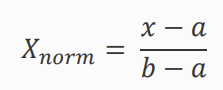
방법2: Standardization
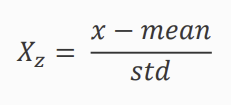
🛸 KNN 모델링 실습
1. 환경 준비
Import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_splitData Loading
path = 'https://raw.githubusercontent.com/DA4BAM/dataset/master/boston.csv'
data = pd.read_csv(path)
data.head()target = medv(타운별 집값(중위수))
2. 데이터 준비
데이터 준비
target = 'medv'
x = data.drop(target, axis=1) # feature: medv 제외 모든 변수
y = data.loc[:, target] # target: medv만 선택
# 학습용/검증용 데이터 분리
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=.2, random_state = 2022)Scaling
KNN 알고리즘을 적용하기 위해서 꼭 필요한 단계
1) 정규화(Normalization)
- Min Max 방식
- 모든 변수(열)의 값을 0 ~ 1 사이 값으로 변환
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 선언
scaler1 = MinMaxScaler()
# train으로 .fit + .transform(적용)
x_train_s1 = scaler1.fit_transform(x_train)
# val은 적용만
x_val_s1 = scaler1.transform(x_val)표준화(Standardization)
- 모든 변수(열)의 값을 평균 = 0, 표준편차 = 1 을 갖도록 변환
- 정규분포의 의미는 아님
scaler2 = StandardScaler()
x_train_s2 = scaler2.fit_transform(x_train)
x_val_s2 = scaler2.transform(x_val)- 스케일링을 수행하게 되면 결과가 넘파이 어레이로 저장되므로, 다루기 쉽게(.describe()를 사용하기 위해) 데이터프레임으로 변환
.describe(): 데이터프레임, 시리즈의 기초 통계량을 보여줌- list(데이터프레임) : 데이터 프레임의 칼럼이름을 반환
x_train_s1 = pd.DataFrame(x_train_s1, columns = list(x))
x_train_s2 = pd.DataFrame(x_train_s2, columns = list(x))- 스케일링 한다고 분포의 모양이 바뀌지는 않음!
- 다음의 3개의 케이스의 분포 그래프는 모두 동일
# 원래 age 변수의 분포
plt.hist(x_train['age'], bins = 30)
plt.show()
# MinMax Scaling 후 분포
plt.hist(x_train_s1['age'], bins = 30)
plt.show()
# Standard Scaling 후 분포
plt.hist(x_train_s2['age'], bins = 30)
plt.show()
모델링
import
# 모델링용
from sklearn.neighbors import KNeighborsRegressor
# 분류모델 사용하고 싶으면 = KNeighborsClassifier
# 회귀모델 평가용
from sklearn.metrics import * # 모든 함수 다 불러와~모델 선언
K=3인 KNN 회귀 모델 선언 -> 가장 가까운 3개 이웃을 사용해 예측
model = KNeighborsRegressor(n_neighbors = 3)모델링(학습)
model.fit(x_train_s1, y_train)검증: 예측
pred = model.predict(x_val_s1)검증: 평가
# MSE
mean_squared_error( y_val, pred )
# RMSE
root_mean_squared_error(y_val, pred)
# MAE: 평균 오차
mean_absolute_error(y_val, pred )
# MAPE : 평균 오차율
mean_absolute_percentage_error(y_val, pred )
# 1 - MAPE : 정확도
1 - mean_absolute_percentage_error(y_val, pred )🛸 7주차 블로그 챌린지
[희망 직무와 직무를 위한 본인의 노력]
아직 2학년이고 배운 것이 많이 없어서 정확한 직무를 찾진 못했다. 하지만 전공을 살려 컴퓨터공학쪽으로 나아가고 싶고, 추후에 내가 원하는 세부적인 직무를 정하고 싶다.
그래서 최대한 다양하게 많은 경험을 하고 싶어서 IT 연합 동아리에서 프론트엔드도 다뤄보고, BDA에서 데이터 모델링도 배우고 있다. 아무래도 데이터의 양이 방대하게 늘어나는 시대에서 데이터에 대해 배우면 좋은 경험이 될 것 같다고 생각했다.
직무 찾기에도 도움이 되는 BDA 강의를 기회가 된다면 내년에도 이이서 듣고 싶다.